
INVESTIGACIÓN
Kits Data Sourcing
Calidad dentro, calidad fuera: Cómo los datos de Kits potencian la IA para uso profesional
El rendimiento de un modelo de IA depende tanto de la calidad de sus datos de entrenamiento como de su arquitectura. En Kits.AI, estamos comprometidos de manera inquebrantable en obtener los datos de la más alta calidad para construir herramientas de IA que estén listas para lanzar para profesionales de la industria musical de todo el mundo.
También reconocemos que las herramientas de música de IA no existen en un vacío. Operamos en una industria que prospera gracias a la creatividad humana, por lo que todos nuestros datos están licenciados directamente de artistas que se benefician económicamente del uso de sus grabaciones.
Este artículo demuestra algunas de las muchas maneras en que prácticas de datos meticulosas proporcionan la base para una IA de alta calidad y ética.
Voces libres de regalías listas para su lanzamiento
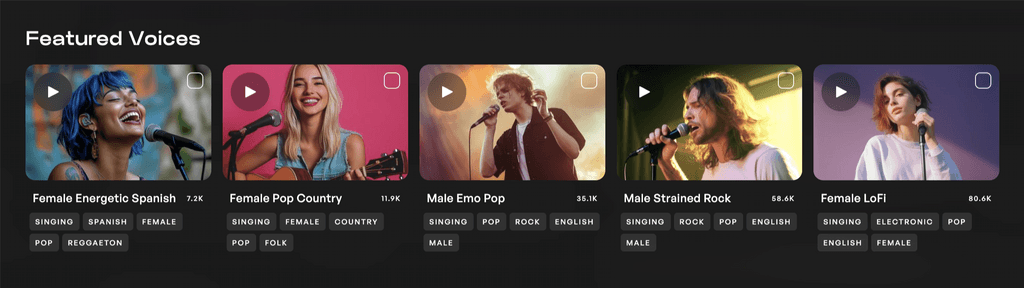
La Biblioteca de Royalty Free de Kits proporciona clones de voz de calidad de estudio que millones de productores de música alrededor del mundo pueden usar en su música con licencias comerciales y libres de regalías. Desde falsetes etéreos hasta tonos de rock distorsionados, esta paleta vocal ofrece a los productores infinitas opciones creativas.
Escucha algunos ejemplos:

Hombre Brillante Pop

Pop Femenino Cálido

Roca Lisa Femenina
Cada voz en la biblioteca se obtiene directamente de un artista que es compensado por el uso de sus datos de entrenamiento. Para respetar las formas rápidamente cambiantes en que la IA se ajusta a sus carreras, estos artistas tienen la opción de optar por no participar en cualquier momento. Nuestros datos de entrenamiento, obtención de datos y prácticas de gestión de datos están certificados como Justamente Entrenados.
Código Abierto vs. Datos de Kits
Los datos de código abierto impulsan muchos proyectos significativos en el espacio de texto a voz y conversión de voz, pero vienen con limitaciones. Los datos de Kits están recopilados y procesados para adherirse a los siguientes pilares de calidad:
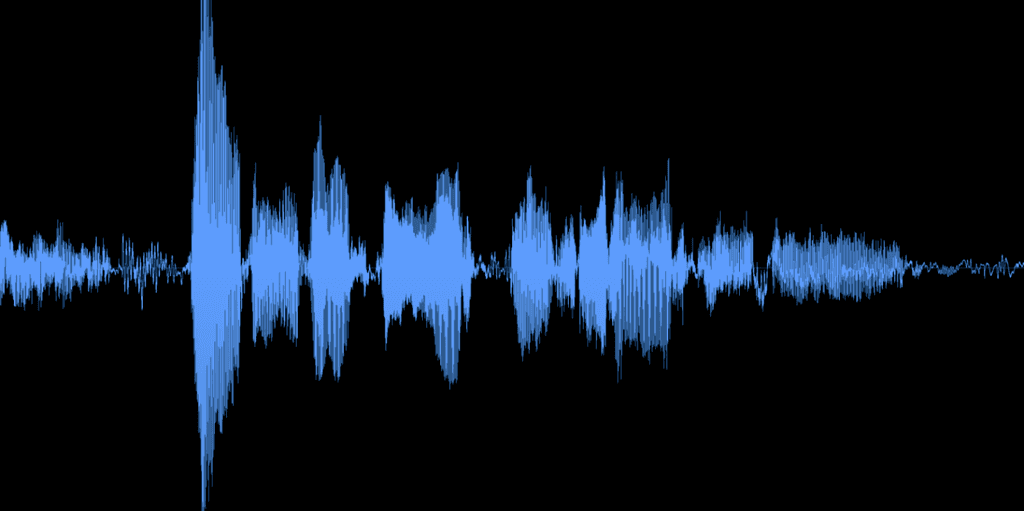
Datos de código abierto con picos altos y RUIDO.
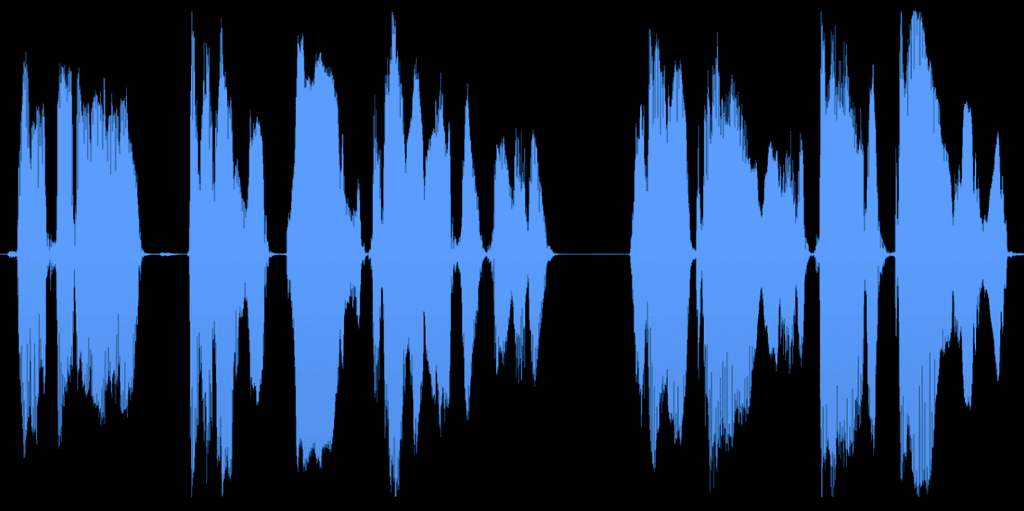
Datos de kits con VOLUMEN CONSISTENTE Y SIN RUIDO.
Consistencia:
Todos los datos de los Kits son procesados manualmente por ingenieros de audio expertos para mantener la consistencia en la respuesta de frecuencia, los niveles de sonoridad máxima y promedio, la rotación de fase, la tasa de muestreo y más. Con conjuntos de datos de código abierto, la inconsistencia en estas áreas puede agregar una variación indeseable que limita la calidad del modelo.
Relación señal-ruido:
Desde la calidad del micrófono hasta el tratamiento acústico, Kits define pautas detalladas para prevenir ruidos no deseados en los datos de entrenamiento. Un nivel de ruido consistentemente bajo en los datos de entrenamiento resulta en una clonación de voz más efectiva y conversiones más limpias.
Limpieza:
La tecnología de división de pistas se ha vuelto sorprendentemente buena. Pero los datos vocales extraídos de las canciones todavía probablemente tendrán reverberación, armonías, fuga instrumental u otros artefactos de división de pistas.
Los datos de kits provienen directamente del micrófono para una grabación garantizada limpia y monofónica.
Post-procesamiento
La ingeniería vocal en sí misma es un arte. Nuestros ingenieros internos procesan meticulosamente cada conjunto de datos para aplicar la cantidad perfecta de pulido estilístico. Consonantes perfectamente comprimidas y vocales claras y resonantes se transmiten para que las voces de Kits sean versátiles y listas para su lanzamiento.
Pesos Pre-entrenados
Cuando clonas una voz con Kits.AI, estás capturando toda la matización, expresividad y sonido natural de esa voz.
Pero tu clon de voz no comienza desde cero. En cambio, comienza con un modelo inicial (o “peso preentrenado”) que comprende las generalidades de cómo suenan las voces. Un buen punto de partida reduce drásticamente el tiempo de entrenamiento y proporciona una base de calidad para tu clon de voz.
A diferencia de los pesos preentrenados de código abierto, que carecen de exposición a datos de canto, los modelos de Kits vienen preentrenados con datos de canto editados a mano, cubriendo un amplio espectro de estilos y técnicas vocales. Escucha algunas comparaciones entre los clones de voz que utilizan pesos preentrenados de código abierto y los clones de voz entrenados con Kits.
Modelo Preentrenado de Código Abierto (VCTK)
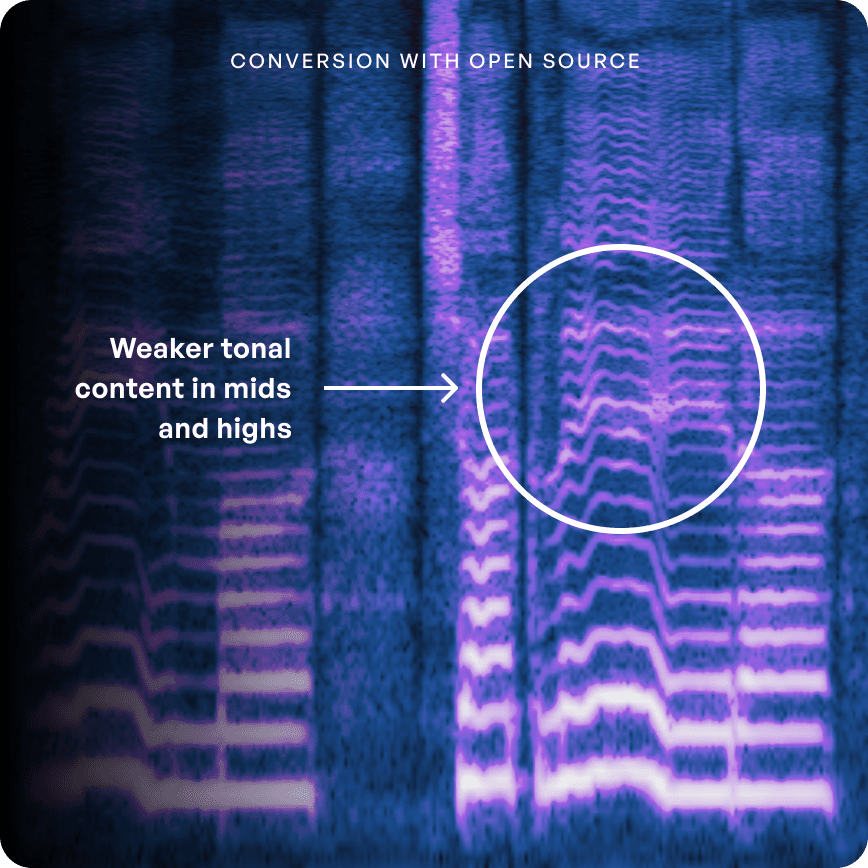
Kits Pre-entrenados
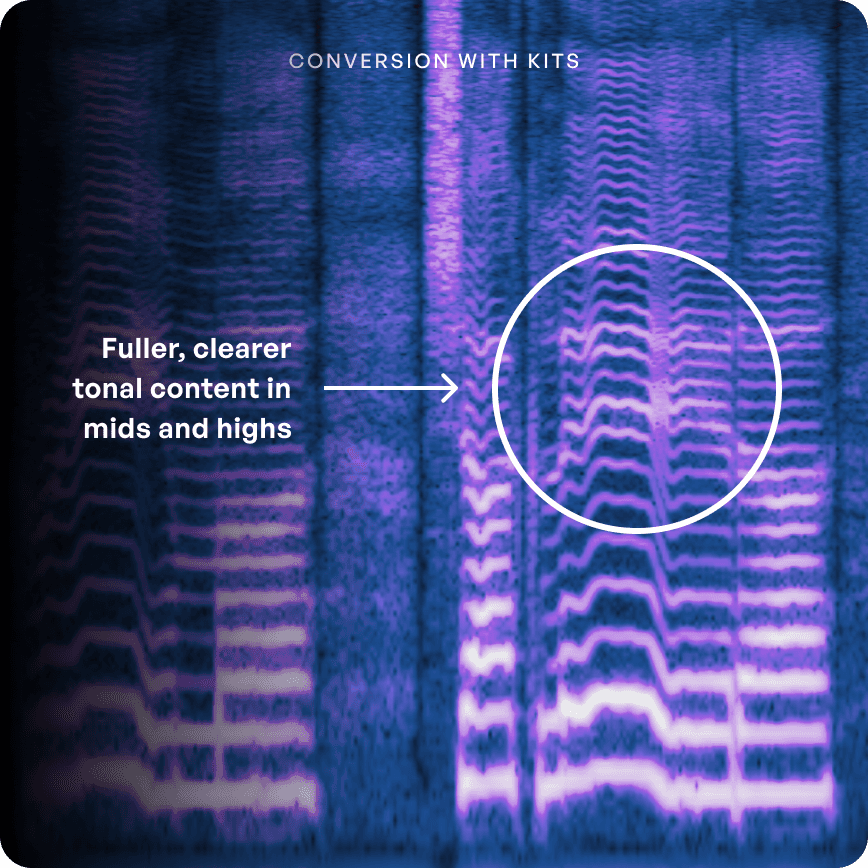
Donde los pesos de Open Source están en gran medida entrenados en datos de habla, los pesos preentrenados de Kits están optimizados para el canto. El resultado: notas más llenas y claras a lo largo (e incluso más allá) del rango de un cantante.
Modelo Preentrenado de Código Abierto (VCTK)
Kits Pre-entrenados
Con Kits, los matices de una actuación vocal se reproducen de manera mucho más realista que con pesos preentrenados de código abierto.
Un compromiso con la IA ética
Creemos que empoderar a la próxima generación de productores de música comienza con empoderar a los artistas cuyas voces hacen esto posible. Es por eso que la investigación de Kits.AI se basa únicamente en datos de entrenamiento con licencia obtenidos directamente de artistas.
Nuestros modelos de voz e instrumentos libres de regalías están certificados como Justamente Entrenados, lo que significa que cada parte de nuestra pipeline de datos, desde la obtención hasta la gestión, ha sido evaluada por su equidad. Esto no es solo un distintivo; es un compromiso con la contribución a la industria creativa en la que operamos.
En Kits.AI, estamos construyendo más que tecnología de IA; estamos creando una base para herramientas de producción musical éticas y de alta calidad que establecen un nuevo estándar en la industria. A medida que continuamos expandiendo nuestra biblioteca de voces y refinando nuestros modelos, seguimos comprometidos con la calidad, la transparencia y la innovación—empoderando a los productores con herramientas en las que pueden confiar.