Comment optimiser l'entraînement d'un modèle vocal d'IA
Écrit par
Publié le
17 septembre 2024
Bien que cela puisse sembler contre-intuitif, un modèle vocal AI de bonne qualité ne nécessite pas de chanteurs ayant un parfait diapason. L'une des erreurs les plus courantes que je rencontre en révisant les soumissions pour notre programme Community Voices est des ensembles de données fortement altérées avec de l'auto-tune. De l'extérieur, il est compréhensible que beaucoup supposent que des ensembles de données parfaitement accordés équivalent à des modèles parfaitement accordés. Dans cet article, nous allons explorer pourquoi l'utilisation de la correction de hauteur peut en fait nuire à la qualité de votre modèle vocal AI, ainsi que d'autres conseils utiles pour entraîner un modèle plus naturel et réaliste.

Plus il y en a, mieux c'est !
Les modèles vocaux AI prospèrent avec des données diversifiées. Si vous téléchargez une chanson de trois minutes et demie dans une basse vocale, le modèle peut sembler génial pour cette chanson particulière, mais il manquera de la polyvalence de la gamme complète d'un chanteur dans la vie réelle. Pour des résultats optimaux, visez au moins 30 minutes de matériel vocal qui couvre une large gamme de hauteurs, de dynamiques et de styles de livraison.
Incorporez tout, des notes douces et délicates aux puissantes vocalises, couvrant le large spectre des capacités d'un chanteur. Cette diversité garantit que votre modèle sonne naturel et polyvalent, capable de performer à travers une large gamme de matériel sans être contraint par un ensemble de données limité.
Bounce en vrai mono !
Une erreur courante est de télécharger de l'audio stéréo au lieu de vrai mono lors de la formation d'un modèle vocal. Kits permet actuellement un maximum de 200 Mo de données d'entraînement, donc faire des pistes en stéréo, même si enregistrées avec un seul microphone, peut inutilement doubler la taille de votre fichier. Cela réduit la quantité de données d'entraînement utilisables.
En vous assurant que vos voix sont enregistrées en vrai mono, vous maximisez la quantité de données d'entraînement et évitez de toucher la limite de taille trop tôt. Même si la stéréo est essentielle pour les productions modernes, les modèles vocaux AI n'exigent que du mono pour l'efficacité.
L'auto-tune et la correction de hauteur ne sont pas nécessaires !
Comme je l'ai mentionné plus tôt, des voix parfaitement accordées ne sont pas requises pour les données d'entraînement. Chaque chanteur, même ceux ayant un diapason exceptionnel, a des variations naturelles dans sa voix. Bien que l'auto-tune Antares AutoTune dur puisse convenir à votre style de production, cela peut aboutir à des modèles AI robotiques et peu naturels.
La clé est de réserver la correction de hauteur pour la post-production. Entraîner votre modèle vocal AI avec des voix naturelles et non traitées produira un son plus réaliste et empêchera votre modèle d'être enfermé dans un style spécifique trop traité.

Réservez les effets pour après !
Des effets comme la réverbération, le délai et la modulation sont excellents pour améliorer les performances vocales, mais ils devraient être évités lors de la création de données d'entraînement. Ces effets peuvent interférer avec le processus d'apprentissage automatique, qui se concentre sur la capture de l'essence naturelle de la voix humaine. Les inclure dans votre ensemble de données peut aboutir à des modèles remplis d'artefacts numériques, les rendant moins réalistes.
Au lieu de cela, concentrez-vous sur la capture de voix sèches et claires. Vous pouvez toujours ajouter des effets plus tard. Si les réflexions de la pièce posent problème, essayez d'enregistrer dans un petit espace comme un placard, ou utilisez un filtre anti-réverbération comme le sE RF-X pour minimiser la réverbération et garantir un ensemble de données plus propre.
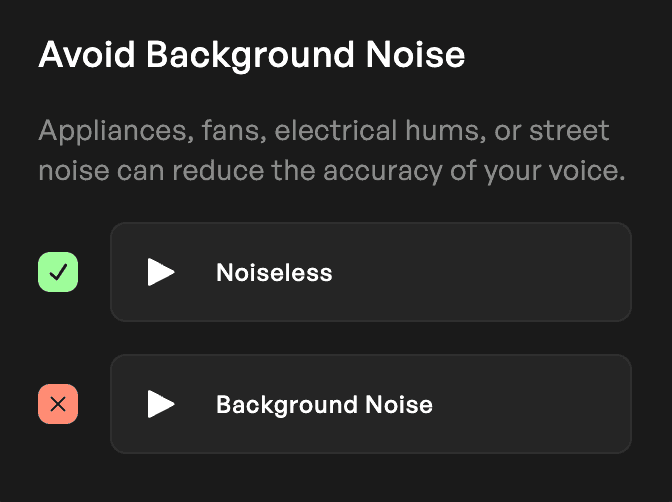
Priorisez la consistance sonore
Bien que la diversité dans la livraison vocale puisse améliorer votre modèle AI, la consistance de la qualité d'enregistrement est cruciale. Le bruit de fond des ventilateurs, des climatiseurs ou d'autres objets domestiques peut affecter négativement le résultat de votre modèle. Faites attention aux niveaux de préampli et à toute distorsion causée par le clipping du microphone ou de l'interface. Soyez attentif à toute incohérence et assurez-vous d'une capture propre, sans distorsion.
De légères variations vocales dues aux changements quotidiens de la voix du chanteur peuvent en fait ajouter de la profondeur à votre modèle, mais assurez-vous que l'aspect technique de votre enregistrement reste cohérent pour maintenir des résultats de haute qualité.
Conclusion
Lors de la construction d'un modèle vocal AI, il est facile de supposer que les techniques de production vocale traditionnelles amélioreront le résultat. Cependant, en suivant ces conseils – utiliser des données naturelles et diverses, maintenir une consistance technique, et réserver les effets pour la post-production – vous créerez un modèle vocal plus réaliste et polyvalent. Kits AI peut débloquer d'incroyables possibilités créatives, et avec la bonne approche, vous pouvez tirer le meilleur parti de vos modèles vocaux AI. Pour des directives d'enregistrement supplémentaires, suivez ce lien pour les recommandations de Kits pour capturer des ensembles de données de haute qualité.
-SK
Sam Kearney est un producteur, compositeur et designer sonore basé à Evergreen, CO.
