
RECHERCHE
Présentation de la conversion de voix chantée sans apprentissage préalable
9 décembre 2024
par Anastasiia Herus
Dans notre mission de fournir les outils les plus puissants pour les créateurs de musique, l'équipe de recherche Kits.AI a développé l'un des premiers modèles de conversion de voix chantée sans entraînement (ZS-SVC) au monde. Ce modèle permet de convertir de l'audio en la voix d'un chanteur cible sans nécessiter d'entraînement.
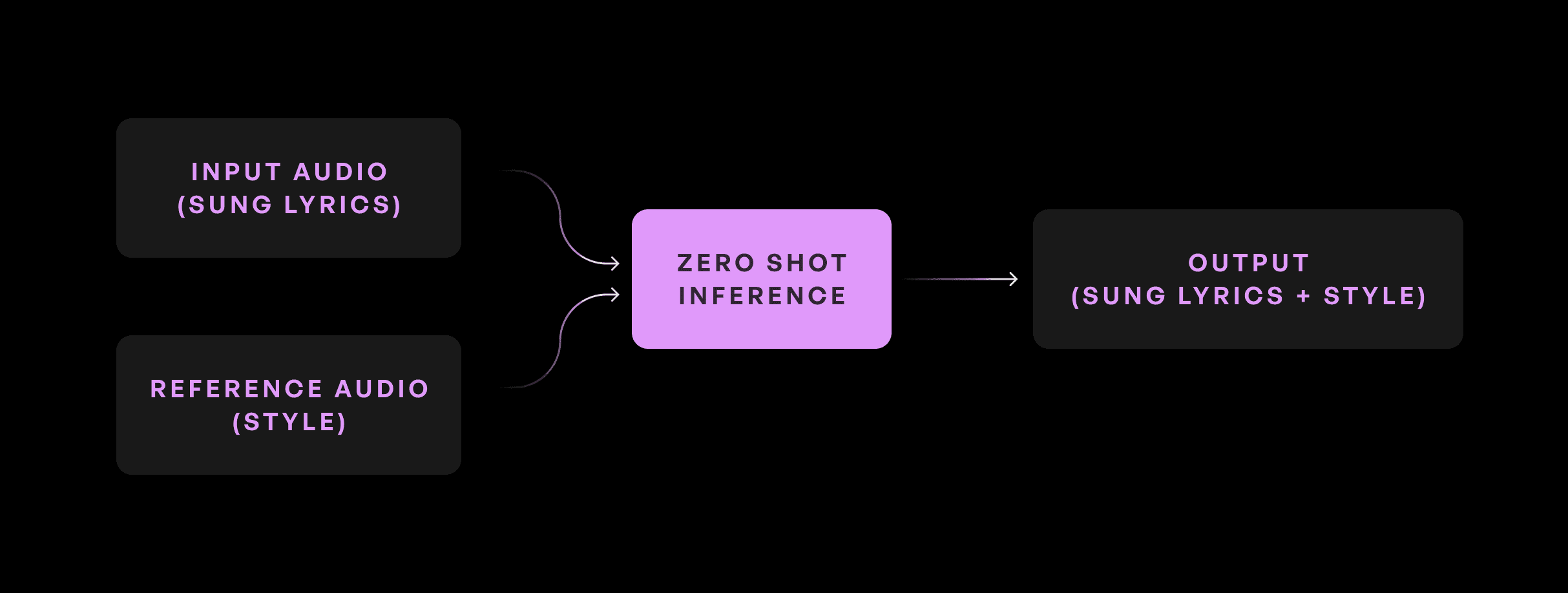
Entrée
Référence chanteur cible
Sortie
Architecture et données
L'architecture du modèle zéro-shot hérite de plusieurs composants clés de l'architecture KVC, y compris l'encodage du contenu, l'encodage de la hauteur et la récupération. L'ajout clé est un module d'encodeur de chanteur, qui calcule un encodage de chanteur à partir du fichier de référence. L'encodage de chanteur est une représentation désentrelacée des voix du chanteur cible qui peut ensuite être utilisée pour la conversion.
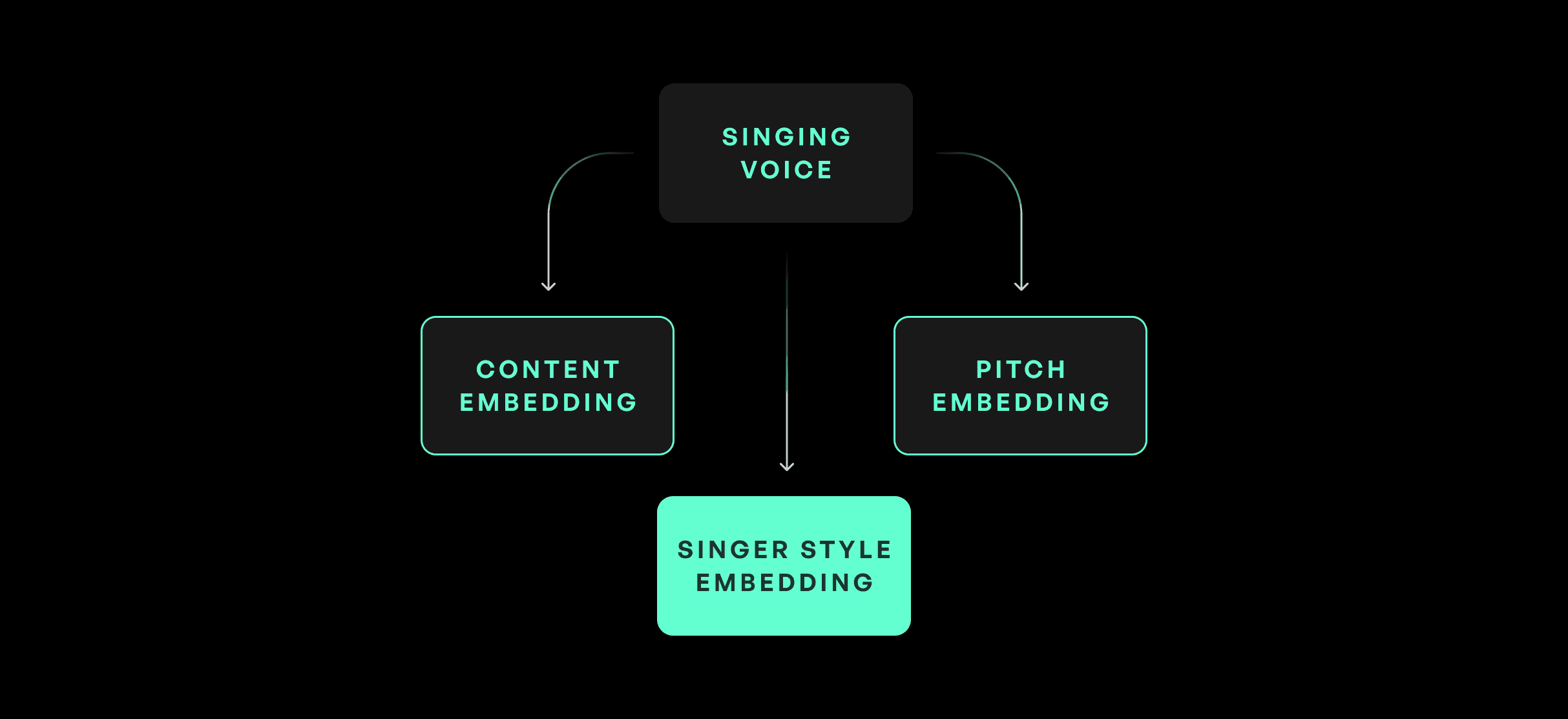
Récupération phonémique pour la préservation de l'accent
Au-delà de la préservation des qualités timbrales du locuteur de référence, le modèle ZS-SVC utilise également un système de récupération phonémique. Comme pour la récupération dans le KVC, cela aide à préserver l'accent du locuteur cible, sans surcorrection ni erreurs de prononciation.
Données
L'optimisation de la qualité des données plutôt que de la quantité a un impact considérable sur les résultats du chant à zéro coup. Le modèle ZS-SVC a été formé sur le jeu de données vocal enregistré en studio sous licence de Kits. Toutes les données sont licenciées directement par les artistes et prétraitées à la main par des ingénieurs du son pour obtenir une qualité de niveau de sortie.
Regardant vers l'avenir
ZS-SVC alimente notre nouvelle fonctionnalité de clonage vocal instantané (IVC), actuellement disponible pour les utilisateurs beta de Kits. D'autres fonctionnalités utilisant ZS-SVC deviendront disponibles pour la communauté Kits élargie avec le temps.
Nous sommes impatients de voir comment les créateurs de musique utilisent ce nouveau modèle pour alimenter leur processus créatif !