कैसे एक एआई वॉयस मॉडल का प्रशिक्षण ऑप्टिमाइज़ करें
द्वारा लिखा गया
प्रकाशित किया गया
17 सितंबर 2024
हालाँकि यह स्पष्ट रूप से विरोधाभासी लग सकता है, एक अच्छा सुनने वाला एआई वॉइस मॉडल गायक की सही पिच की आवश्यकता नहीं होती है। जब मैं हमारे कम्युनिटी वॉयसेस कार्यक्रम के लिए सबमिशन की समीक्षा कर रहा होता हूँ, तो मुझे एक सामान्य गलती यह देखी जाती है कि डेटा सेट को ऑटो-ट्यून के साथ बहुत अधिक संशोधित किया गया है। बाहर से, यह समझना संभव है कि कई लोग यह मानते हैं कि पिच-परफेक्ट डेटा सेट का मतलब पिच-परफेक्ट मॉडल है। इस पोस्ट में, हम यह समझेंगे कि पिच सुधार का उपयोग करने से आपके एआई वॉइस मॉडल की गुणवत्ता वास्तव में कैसे प्रभावित हो सकती है, साथ ही एक अधिक स्वाभाविक, वास्तविकता से मिलते-जुलते मॉडल को प्रशिक्षित करने के लिए अन्य सहायक सुझाव भी।

जितना अधिक, उतना बेहतर!
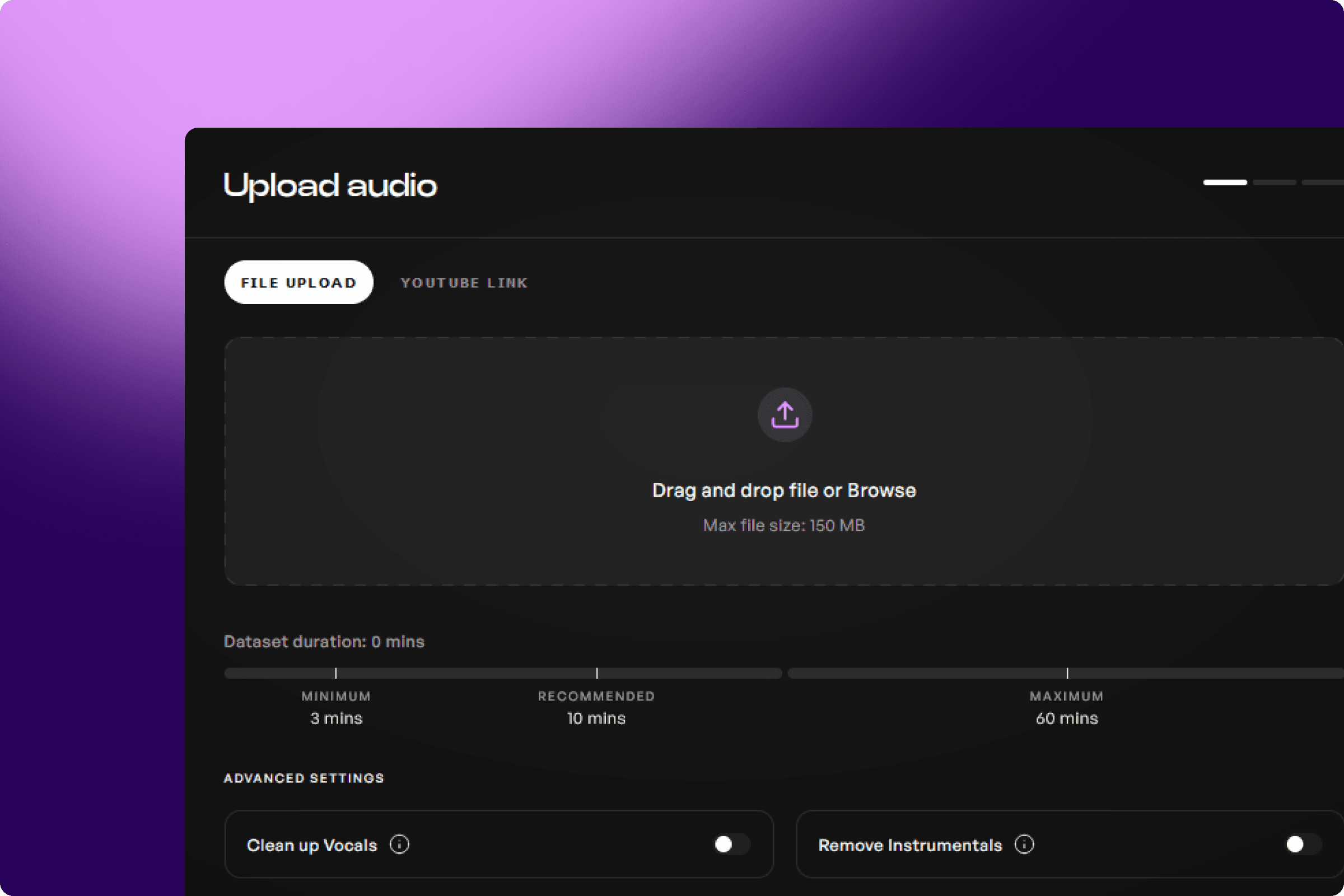
एआई वोकल मॉडल विविध डेटा पर फलते-फूलते हैं। यदि आप एक तीन-से-डेढ़-मिनट का गाना कम वोकल रेंज में अपलोड करते हैं, तो मॉडल उस विशेष गाने के लिए अद्भुत लग सकता है, लेकिन यह एक असली जीवन के गायक की पूरी रेंज की बहुपरकता से वंचित रहेगा। उत्तम परिणामों के लिए, कम से कम 30 मिनट का वोकल सामग्री रखने का लक्ष्य रखें जो विभिन्न पिचों, डायनामिक्स और डिलीवरी शैलियों का व्यापक दायरा कवर करे।
सबसे नाज़ुक, हल्के नोटों से लेकर पूर्ण ऊर्जा वाले बेल्ट तक सबको शामिल करें, जिससे गायक की क्षमताओं का व्यापक स्पेक्ट्रम कवर होता है। यह विविधता यह सुनिश्चित करती है कि आपका मॉडल स्वाभाविक और बहुपरक सुनाई दे, जो एक सीमित डेटा सेट द्वारा सीमित होने के बिना विभिन्न प्रकार के सामग्री में प्रदर्शन करने में सक्षम है।
सच्चे मोनो में बाउंस करें!
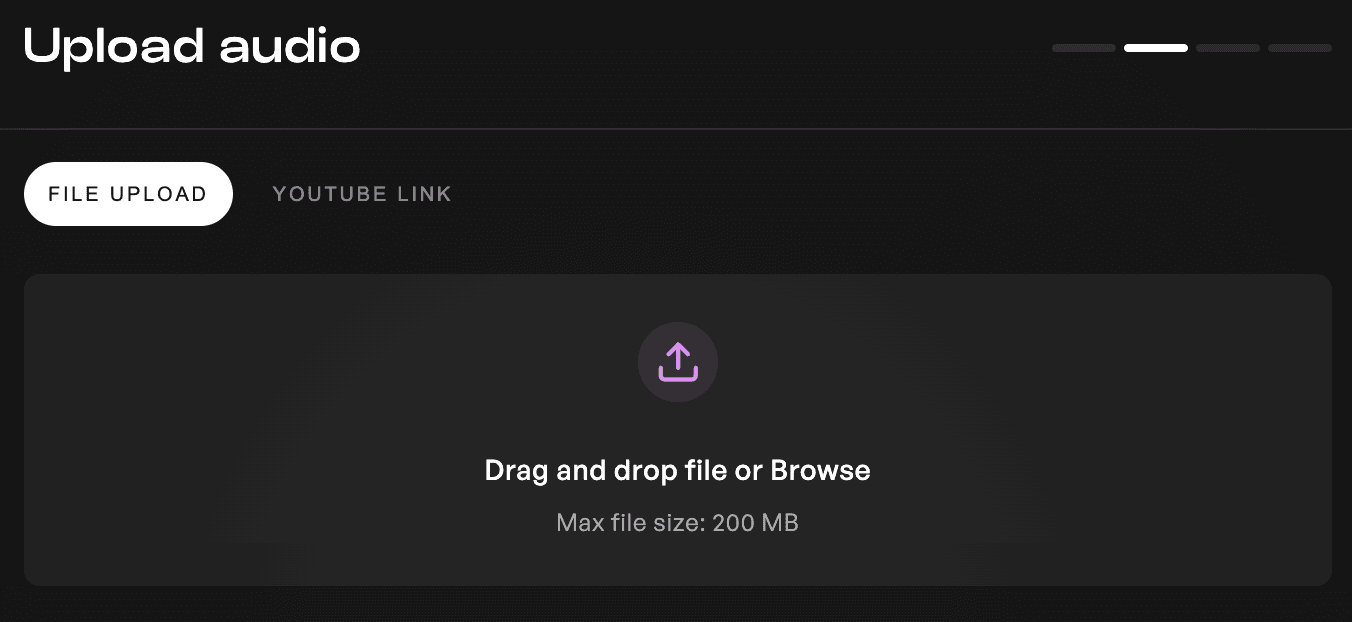
एक सामान्य गलती यह है कि वॉइस मॉडल को प्रशिक्षित करने के लिए स्टीरियो ऑडियो अपलोड किया जाता है, जबकि यह सच्चे मोनो में होना चाहिए। किट्स वर्तमान में अधिकतम 200 एमबी प्रशिक्षण डेटा की अनुमति देता है, इसलिए ट्रैक्स को स्टीरियो में बाउंस करना, भले ही एक ही माइक्रोफ़ोन से रिकॉर्ड किया गया हो, आपके फ़ाइल आकार को अनावश्यक रूप से दोगुना कर सकता है। इससे उपयोगी प्रशिक्षण डेटा की मात्रा में कमी आती है।
यह सुनिश्चित करके कि आपके वोकल सच्चे मोनो में बाउंस किए गए हैं, आप प्रशिक्षण डेटा की मात्रा को अधिकतम बनाते हैं और जल्दी आकार सीमा तक नहीं पहुँचते। हालांकि स्टीरियो आधुनिक प्रस्तुतियों के लिए आवश्यक है, एआई वॉयस मॉडल केवल दक्षता के लिए मोनो की आवश्यकता होती है।
ऑटोट्यून और पिच सुधार की आवश्यकता नहीं है!
जैसा कि मैंने पहले उल्लेख किया, पिच-परफेक्ट वोकल्स प्रशिक्षण डेटा के लिए आवश्यक नहीं होते हैं। हर गायक, यहां तक कि जिनके पास असाधारण पिच होता है, उनके स्वर में प्राकृतिक भिन्नताएँ होती हैं। जबकि हार्ड-ट्यून Antares AutoTune आपके उत्पादन शैली के लिए उपयुक्त हो सकता है, यह रोबोटिक, अप्राकृतिक-सुनने वाले एआई मॉडलों का परिणाम दे सकता है।
चाबी यह है कि पिच सुधार को पोस्ट-प्रोडक्शन के लिए बचाना चाहिए। आपके एआई वॉयस मॉडल को प्राकृतिक, अप्रकृत वोकल्स के साथ प्रशिक्षित करने से अधिक वास्तविक ध्वनि प्राप्त होगी और आपके मॉडल को एक विशिष्ट, बहुत अधिक प्रोसेस्ड स्टाइल में बंद होने से रोका जाएगा।

इफेक्ट्स को पोस्ट के लिए बचाएं!
रीवर्ब, डिले और मॉड्यूलेशन जैसे इफेक्ट्स वोकल प्रदर्शन को बढ़ाने के लिए बहुत अच्छे होते हैं, लेकिन इन्हें प्रशिक्षण डेटा बनाते समय से बचना चाहिए। ये प्रभाव मशीन लर्निंग प्रक्रिया में हस्तक्षेप कर सकते हैं, जो मानव स्वर के प्राकृतिक सार को पकड़ने पर ध्यान केंद्रित करता है। अपने डेटा सेट में इन्हें शामिल करने से मॉडल डिजिटल कलाकृतियों से भरे हो सकते हैं, जिससे वे कम जीवन्त सुनाई देते हैं।
इसके बजाय, सूखी, साफ वोकल्स को पकड़ने पर ध्यान केंद्रित करें। आप हमेशा बाद में प्रभाव जोड़ सकते हैं। यदि कमरे की प्रतिध्वनि एक समस्या है, तो एक छोटे स्थान जैसे कि कोठरी में रिकॉर्ड करने की कोशिश करें, या रीवर्ब कम करने और एक साफ डेटा सेट सुनिश्चित करने के लिए sE RF-X जैसे एक प्रतिबिंब फ़िल्टर का उपयोग करें।
ध्वनि स्थिरता को प्राथमिकता दें
हालाँकि वोकल डिलीवरी में विविधता आपके एआई मॉडल को वर्धित कर सकती है, रिकॉर्डिंग गुणवत्ता में स्थिरता महत्वपूर्ण है। पंखे, एयर कंडीशनरों, या अन्य घरेलू वस्तुओं का बैकग्राउंड शोर आपके मॉडल के परिणाम को नकारात्मक रूप से प्रभावित कर सकता है। प्रीamp स्तरों और माइक्रोफोन या इंटरफ़ेस को क्लिपिंग के कारण उत्पन्न किसी भी विकृति पर ध्यान दें। किसी भी असंगतताओं के लिए कान रखें और एक साफ, विकृति-मुक्त कैप्चर सुनिश्चित करें।
गायक की आवाज़ में दैनिक परिवर्तनों के कारण होने वाले हल्के वोकल परिवर्तनों से वास्तव में आपके मॉडल को गहराई मिल सकती है, लेकिन सुनिश्चित करें कि आपकी रिकॉर्डिंग का तकनीकी पहलू स्थिर रहे ताकि उच्च गुणवत्ता के परिणाम बनाए रख सकें।
निष्कर्ष
जब एक एआई वॉइस मॉडल बनाते हैं, तो यह सोच लेना आसान है कि पारंपरिक वोकल उत्पादन तकनीक परिणाम में सुधार लाएगी। हालाँकि, इन सुझावों का पालन करके – प्राकृतिक, विविध डेटा का उपयोग करना, तकनीकी स्थिरता बनाए रखना, और पोस्ट-प्रोडक्शन के लिए प्रभावों को बचाना – आप एक अधिक वास्तविक, बहुपरक वॉइस मॉडल बनाएंगे। Kits AI अद्भुत रचनात्मक संभावनाएँ खोल सकता है, और सही दृष्टिकोण के साथ, आप अपने एआई वॉइस मॉडलों का सबसे अच्छा लाभ उठा सकते हैं। अतिरिक्त रिकॉर्डिंग दिशा-निर्देशों के लिए, इस लिंक का पालन करें जो किट्स की उच्च गुणवत्ता वाले डेटा सेट कैप्चर करने के लिए अनुशंसाएँ हैं।
-SK
सैम कियरनी एक उत्पादनकर्ता, संगीतकार और ध्वनि डिज़ाइनर हैं, जो एवरग्रीन, CO में स्थित हैं।