
अनुसंधान
शून्य-शॉट गायक आवाज़ रूपांतरण का परिचय
9 दिसंबर, 2024
अनास्तासिया हेरस द्वारा
हमारे संगीत निर्माताओं के लिए सबसे शक्तिशाली उपकरण प्रदान करने के मिशन में, Kits.AI रिसर्च टीम ने दुनिया के पहले Zero-Shot सिंगिंग वॉयस कन्वर्शन (ZS-SVC) मॉडल में से एक विकसित किया है। यह मॉडल ऑडियो को लक्षित गायक की आवाज़ में बदलने की अनुमति देता है बिना प्रशिक्षण की आवश्यकता के।
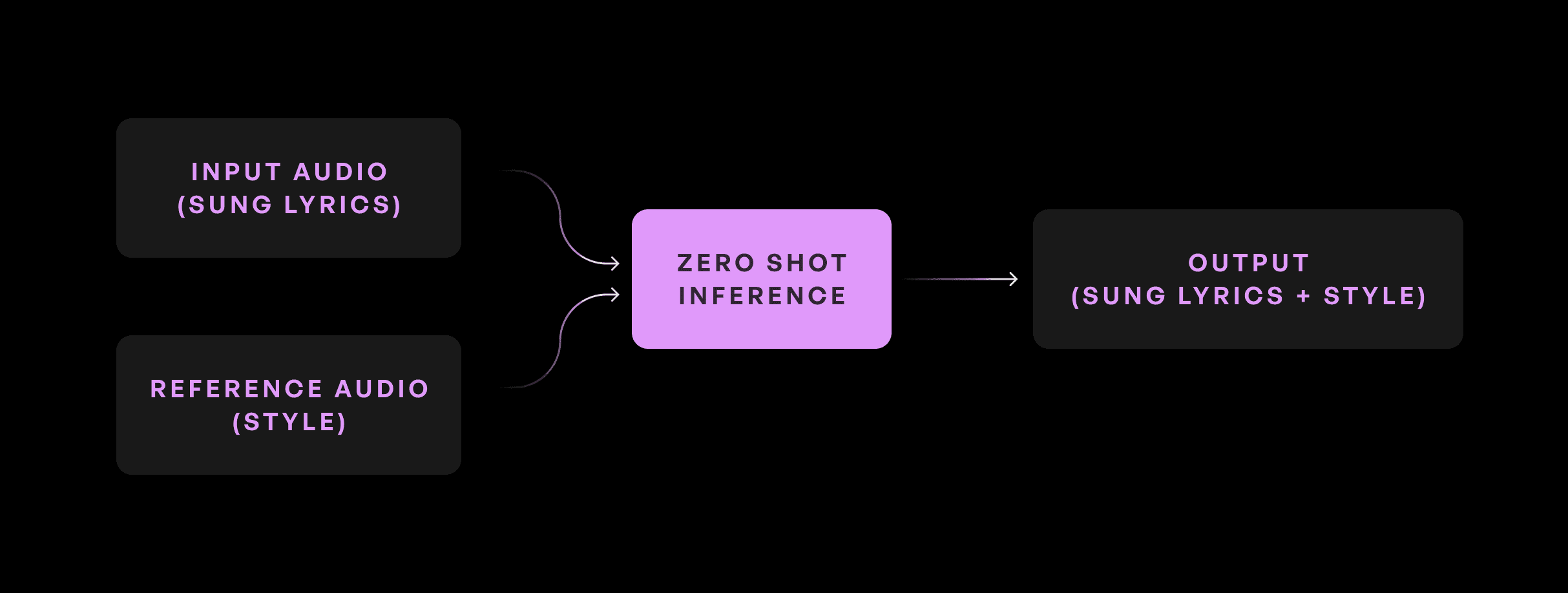
इनपुट
लक्ष्य गायक संदर्भ
आउटपुट
आर्किटेक्चर और डेटा
ज़ीरो-शॉट मॉडल आर्किटेक्चर KVC आर्किटेक्चर, के कई मुख्य घटकों को विरासत में लेता है, जिसमें सामग्री एन्कोडिंग, पिच एन्कोडिंग और पुनःप्राप्ति शामिल हैं। मुख्य जोड़ एक गायक एन्कोडर मॉड्यूल है, जो संदर्भ फ़ाइल से एक गायक एम्बेडिंग की गणना करता है। गायक एम्बेडिंग लक्षित गायक के वोकल्स का एक अलग प्रतिनिधित्व है जिसका उपयोग फिर रूपांतरण के लिए किया जा सकता है।
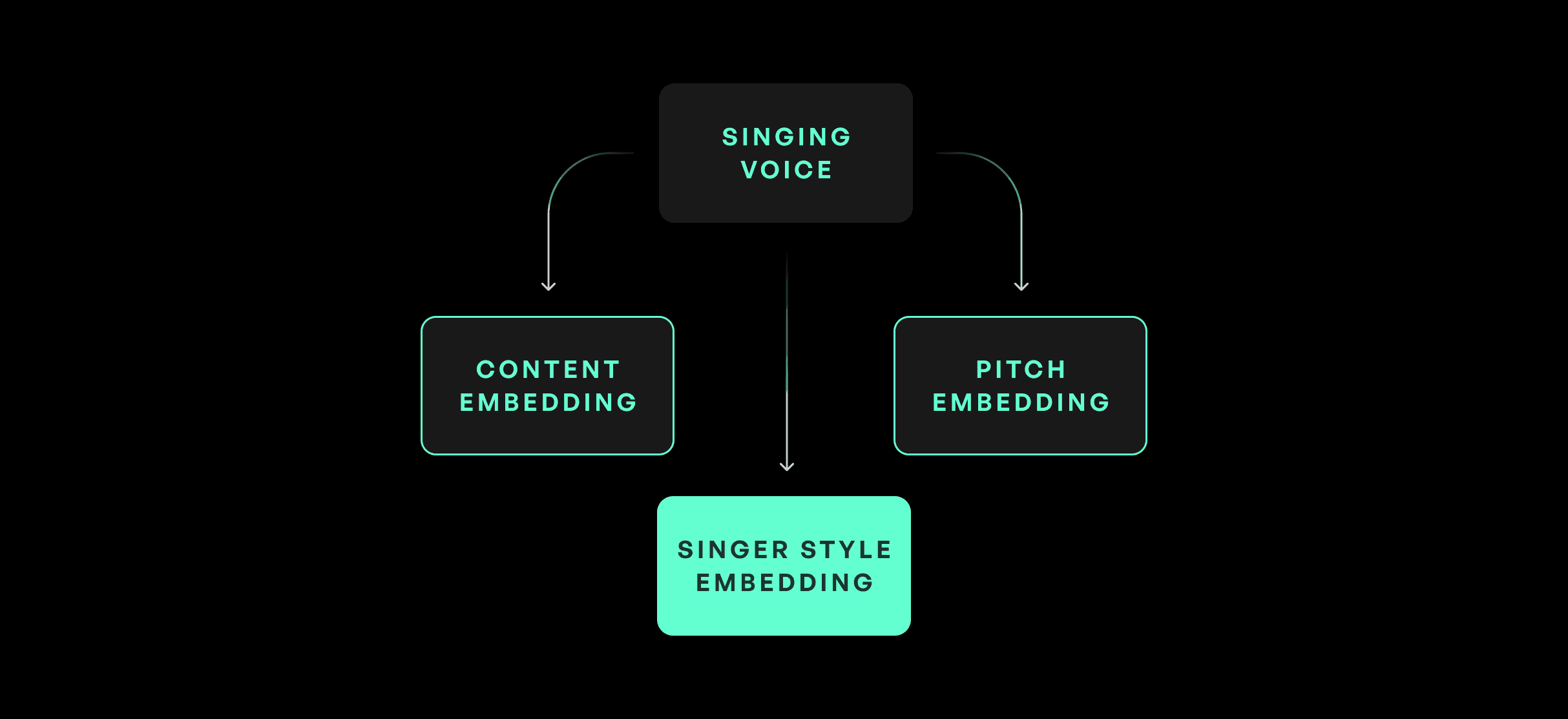
उच्चारण संबंधी पुनर्प्राप्ति के लिए लहजे का संरक्षण
संदर्भ वक्ता की ध्वनि विशेषताएँ संरक्षित करने के अलावा, ZS-SVC मॉडल एक ध्वन्यात्मक पुनःप्राप्ति प्रणाली का भी उपयोग करता है। KVC में पुनःप्राप्ति के समान, यह लक्षित वक्ता के उच्चारण को बनाए रखने में मदद करता है, बिना अधिक सुधार किए और उच्चारण त्रुटियों का कारण बने।
डेटा
डेटा की गुणवत्ता को मात्रा पर प्राथमिकता देना जीरो-शॉट गाने के परिणामों पर अत्यधिक प्रभाव डालता है। ZS-SVC मॉडल किट्स के लाइसेंस प्राप्त स्टूडियो में रिकॉर्ड किए गए वोकल डेटासेट पर प्रशिक्षित किया गया था। सभी डेटा कलाकारों से सीधे लाइसेंस प्राप्त हैं और ऑडियो इंजीनियरों द्वारा मैन्युअल रूप से पूर्व-संसाधित किए गए हैं ताकि रिलीज स्तर की गुणवत्ता प्राप्त हो सके।
आगे देखते हुए
ZS-SVC हमारे नए इंस्टेंट वॉयस क्लोनिंग (IVC) फीचर को शक्ति देता है, जो वर्तमान में किट्स बीटा उपयोगकर्ताओं के लिए उपलब्ध है। समय के साथ, ZS-SVC का उपयोग करके अधिक फीचर्स व्यापक किट्स समुदाय के लिए उपलब्ध हो जाएंगे।
हम देखना चाहते हैं कि संगीत निर्माता इस नए मॉडल का उपयोग अपने रचनात्मक प्रक्रिया को शक्ति देने के लिए कैसे करते हैं!