AI 음성 모델 훈련 최적화 방법
작성자
게시됨
2024년 9월 17일
비록 직관에 반하는 듯 보일 수 있지만, 훌륭한 음질의 AI 음성 모델은 완벽한 음정을 가진 가수를 필요로 하지 않습니다. 우리 커뮤니티 보이스 프로그램에 제출물을 리뷰할 때 가장 흔히 발견하는 실수 중 하나는 오토튠으로 심하게 변형된 데이터셋입니다. 외부에서 보면, 많은 사람들이 음정 완벽한 데이터셋이 음정 완벽한 모델과 같다라고 이해할 수 있습니다. 이 포스트에서는 피치 수정이 실제로 AI 음성 모델의 품질에 해로울 수 있는 이유와 더 자연스럽고 현실적인 모델을 훈련하기 위한 다른 유용한 팁을 탐구해 보겠습니다.

더 많을수록 좋다!
AI 음성 모델은 다양한 데이터에서 번창합니다. 만약 낮은 음성 범위의 3분 30초짜리 곡을 업로드하면, 해당 특정 곡에 대해 모델이 훌륭하게 들릴 수 있지만, 실제 가수의 전체 범위의 다재다능함이 부족해질 것입니다. 최적의 결과를 얻으려면, 다양한 음정, 다이내믹, 전달 스타일을 아우르는 최소 30분의 음성 자료를 목표로 하세요.
부드럽고 섬세한 음으로부터 강한 에너지의 벨트까지 모든 것을 포함하여 가수의 능력을 폭넓게 다뤄야 합니다. 이 다양성은 모델이 자연스럽고 다재다능하게 들릴 수 있도록 보장하며, 한정된 데이터셋에 의해 제약받지 않고 광범위한 자료에 대해 성능을 발휘할 수 있게 합니다.
진정한 모노로 바운스하라!
일반적인 간과는 음성 모델을 훈련할 때 진정한 모노 대신 스테레오 오디오를 업로드하는 것입니다. Kits는 현재 최대 200MB의 훈련 데이터를 허용하므로, 단일 마이크로폰으로 녹음했더라도 스테레오로 트랙을 바운스하면 불필요하게 파일 크기가 두 배로 늘어날 수 있습니다. 이는 사용 가능한 훈련 데이터의 양을 줄입니다.
여러분의 음성이 진정한 모노로 바운스되도록 보장함으로써 훈련 데이터의 양을 극대화하고 너무 빨리 크기 제한에 도달하는 것을 피할 수 있습니다. 비록 스테레오가 현대 제작에 필수적이지만, AI 음성 모델은 효율성을 위해 오직 모노만 필요합니다.
오토튠과 피치 교정은 필요 없다!
앞서 언급했듯이, 완벽한 음정의 VOCAL은 훈련 데이터에 필요하지 않습니다. 모든 가수는, 비록 그들 중 일부가 뛰어난 음정을 가지더라도, 목소리에 자연스러운 변화를 가지고 있습니다. 하드 튠된 안타레스 오토튠이 여러분의 제작 스타일에 맞을 수 있지만, 로봇처럼 비자연스럽게 들리는 AI 모델을 초래할 수 있습니다.
핵심은 후반 작업을 위해 피치 수정을 남기는 것입니다. 자연스럽고 가공되지 않은 목소리로 AI 음성 모델을 훈련하면 더 현실적인 사운드를 얻을 수 있으며, 여러분의 모델이 특정하고 과도하게 가공된 스타일에 고착되지 않도록 방지할 수 있습니다.

효과는 후반 작업을 위해 남겨라!
리버브, 딜레이 및 모듈레이션과 같은 효과는 음성 성능을 향상시키는 데 좋지만, 훈련 데이터를 생성할 때는 피해야 합니다. 이러한 효과는 인간 음성의 자연스러운 본질을 캡처하는 데 중점을 두는 기계 학습 프로세스에 방해가 될 수 있습니다. 데이터셋에 포함될 경우 모델에 디지털 아티팩트가 가득 차서 덜 생동감 있게 들릴 수 있습니다.
대신 건조하고 깨끗한 음성을 캡처하는 데 집중하세요. 나중에 항상 효과를 추가할 수 있습니다. 방 반사가 문제라면, 옷장과 같은 작은 공간에서 녹음하거나 리플렉션 필터인 sE RF-X를 사용하여 리버브를 최소화하고 더 깨끗한 데이터셋을 확보하세요.
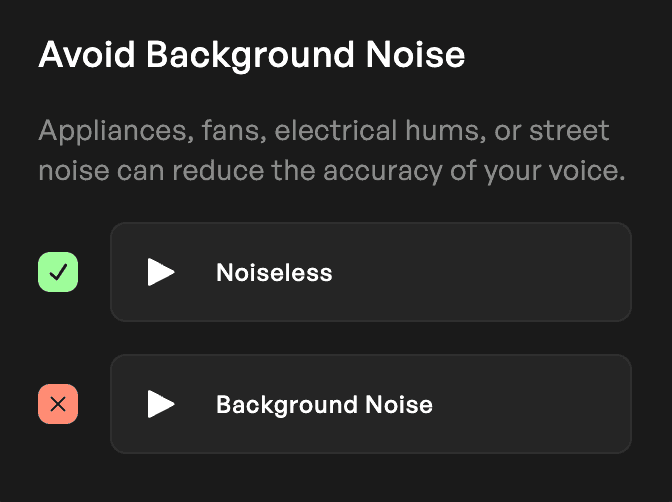
음향 일관성을 우선시하라!
음성 전달의 다양성이 AI 모델을 향상시킬 수 있지만, 녹음 품질의 일관성은 매우 중요합니다. 팬, 에어컨 또는 기타 가정용 물품으로 인한 배경 소음은 모델의 결과에 부정적인 영향을 미칠 수 있습니다. 프리앰프 레벨과 마이크 또는 인터페이스에서 클리핑으로 인한 왜곡에 주의하세요. 불일치를 확인하고 깨끗하고 왜곡 없는 캡처가 이루어지도록 하세요.
가수의 목소리에 따른 약간의 변동은 실제로 모델에 깊이를 더할 수 있지만, 녹음의 기술적인 측면이 일관되게 유지되어 고품질 결과를 유지해야 합니다.
결론
AI 음성 모델을 구축할 때, 전통적인 음성 제작 기술이 결과를 개선할 것이라고 쉽게 가정할 수 있습니다. 그러나 이러한 팁을 따름으로써–자연스럽고 다양한 데이터 사용, 기술적인 일관성 유지, 후반 작업을 위한 효과 저장–보다 현실적이고 다재다능한 음성 모델을 만들 수 있습니다. Kits AI는 믿을 수 없는 창의적 가능성을 열어줄 수 있으며, 올바른 접근 방식을 통해 AI 음성 모델에서 최대의 결과를 얻을 수 있습니다. 추가 녹음 지침을 위해 고품질 데이터셋을 캡처하기 위한 Kits의 권장 사항에 대한 이 링크를 따르세요.
-SK
Sam Kearney는 콜로라도 에버그린에 거주하는 프로듀서이자 작곡가, 사운드 디자이너입니다.
