
연구
Kits Data Sourcing
품질이 들어가면 품질이 나옵니다: 키트 데이터가 전문적인 사용을 위한 AI를 어떻게 지원하는가
AI 모델의 성능은 아키텍처만큼이나 훈련 데이터의 품질에 달려 있습니다. Kits.AI에서는 전 세계 음악 산업 전문가들을 위해 출시 준비가 완료된 AI 도구를 만들기 위해 가장 높은 품질의 데이터를 확보하는 데 타협하지 않습니다.
우리는 또한 AI 음악 도구가 독립적으로 존재하지 않음을 인식합니다. 우리는 인간의 창의성이 번창하는 산업에서 활동하며, 우리 데이터는 모든 경우에 그들의 녹음을 사용하는 것에서 재정적 이익을 얻는 아티스트들로부터 직접 라이센스가 부여됩니다.
이 기사는 세심한 데이터 관행이 고품질의 윤리적 AI를 위한 기반을 제공하는 여러 가지 방법을 보여줍니다.
출시 준비 완료된 로열티 없는 목소리
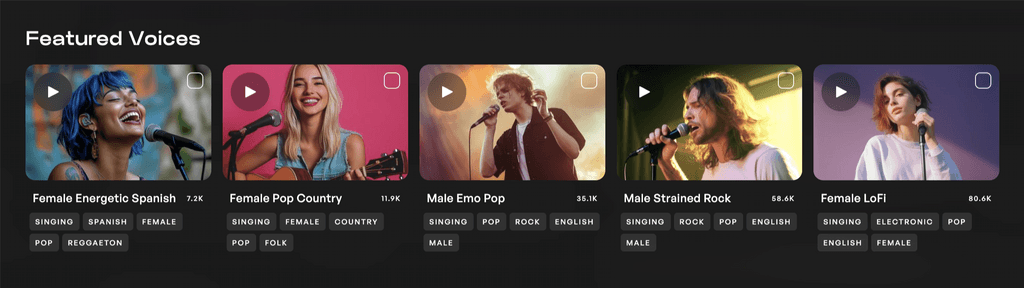
이 키츠 로열티 프리 라이브러리는 전 세계 수백만 음악 제작자가 상업용 로열티 프리 라이선스로 음악에 사용할 수 있는 스튜디오 품질의 음성 클론을 제공합니다. 공기 같은 팔세토부터 프라이드 록 톤까지, 이 음성 팔레트는 제작자에게 무한한 창의적 선택을 제공합니다.
몇 가지 예를 들어 들어보세요:

남성 밝은 팝

여성 따뜻한 팝

여성 매끄러운 바위
라이브러리의 각 음성은 자신의 교육 데이터 사용에 대한 보상을 받는 아티스트로부터 직접 수집됩니다. AI가 그들의 경력에 적응하는 빠르게 변화하는 방식에 대한 존중으로, 이 아티스트들은 언제든지 선택 해제할 수 있는 옵션이 있습니다. 우리의 교육 데이터, 데이터 소싱 및 데이터 관리 관행은 공정하게 훈련받았다고 인증되었습니다.
오픈 소스 vs. 키트 데이터
오픈 소스 데이터는 텍스트 음성 변환 및 음성 변환 분야에서 많은 의미 있는 프로젝트를 지원하지만, 한계가 있습니다. 키트 데이터는 다음 품질 기준을 준수하도록 선별되고 처리됩니다:
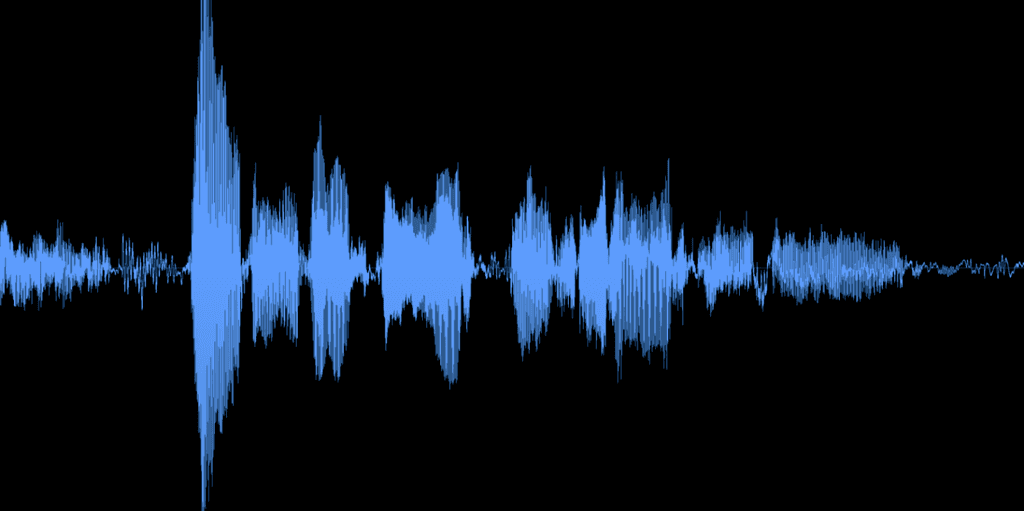
시끄러운 피크와 NOISE가 있는 오픈 소스 데이터.
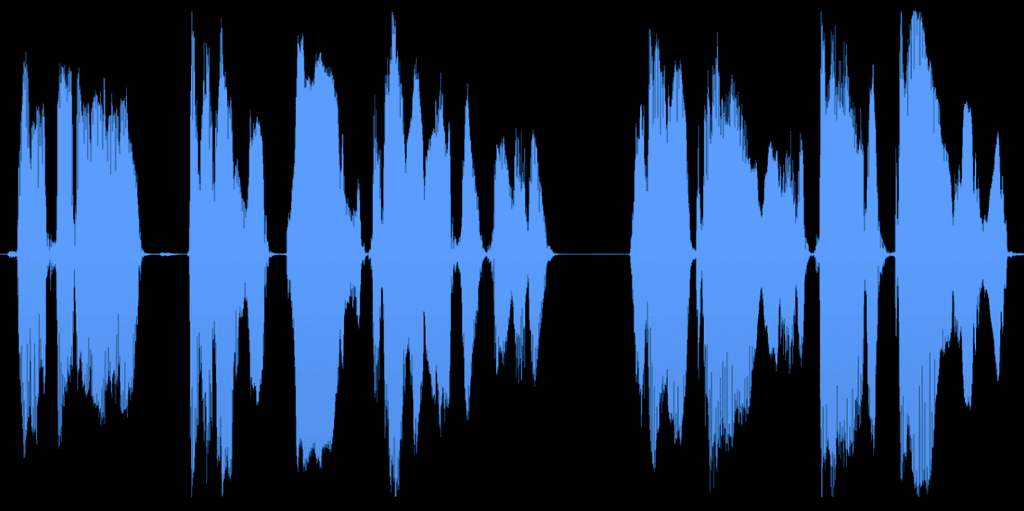
일관된 볼륨과 잡음 없는 킷 데이터.
일관성:
모든 키트 데이터는 주파수 반응, 피크 및 평균 음량 수준, 위상 회전, 샘플링 속도 등을 유지하기 위해 전문 오디오 엔지니어에 의해 수동으로 처리됩니다. 오픈 소스 데이터 세트와 함께 이러한 영역의 불일치는 모델 품질을 제한하는 바람직하지 않은 변화를 추가할 수 있습니다.
신호 대 잡음 비율:
마이크 품질에서 음향 처리에 이르기까지 Kits는 훈련 데이터에서 원치 않는 소음을 방지하기 위한 세부 지침을 정의합니다. 훈련 데이터에서 일관되게 낮은 소음 바닥은 더 효과적인 음성 복제와 깨끗한 변환을 가져옵니다.
청결:
스템 분할 기술은 놀라울 정도로 좋아졌습니다. 그러나 노래에서 추출된 음성 데이터는 여전히 리버브, 하모니, 악기 간섭 또는 기타 스템 분할 아티팩트를 가질 가능성이 높습니다.
킷 데이터는 마이크에서 직접 수집되어 보장된 깨끗하고 모노포닉한 녹음을 제공합니다.
후처리
보컬 엔지니어링 자체가 하나의 예술입니다. 저희 내부 엔지니어들은 각 데이터 세트를 면밀하게 처리하여 완벽한 스타일링 마무리를 적용합니다. 완벽하게 압축된 자음과 맑고 공명하는 모음이 Kits 음성을 다재다능하고 출시 준비가 완료된 상태로 만듭니다.
사전 훈련된 가중치
당신이 Kits.AI로 목소리를 복제할 때, 당신은 그 목소리의 모든 뉘앙스, 표현력 및 자연스러운 소리를 포착하는 것입니다.
하지만 당신의 목소리 복제는 제로에서 시작하지 않습니다. 대신, 일반적인 목소리의 음색을 이해하는 스타터 모델(또는 “사전 훈련된 가중치”)로 시작합니다. 좋은 출발점은 훈련 시간을 극적으로 단축하고 목소리 복제를 위한 품질 기준을 제공합니다.
노래 데이터에 대한 노출이 부족한 오픈 소스 사전 훈련된 가중치와 달리, Kits 모델은 다양한 보컬 스타일과 기법을 포Cover하는 손편집된 노래 데이터에 대해 사전 훈련되어 있습니다. 오픈 소스 사전 훈련된 가중치를 사용하는 목소리 복제와 Kits로 훈련된 목소리 복제의 몇 가지 비교를 들어보세요.
오픈 소스 사전 훈련 모델 (VCTK)
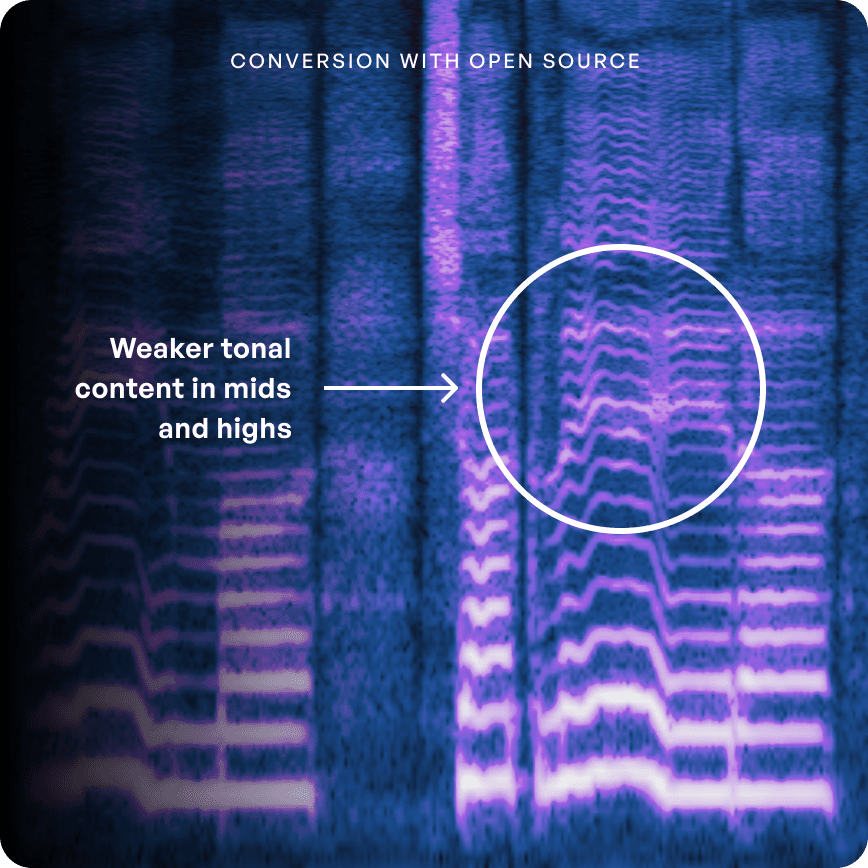
사전 훈련된 키트
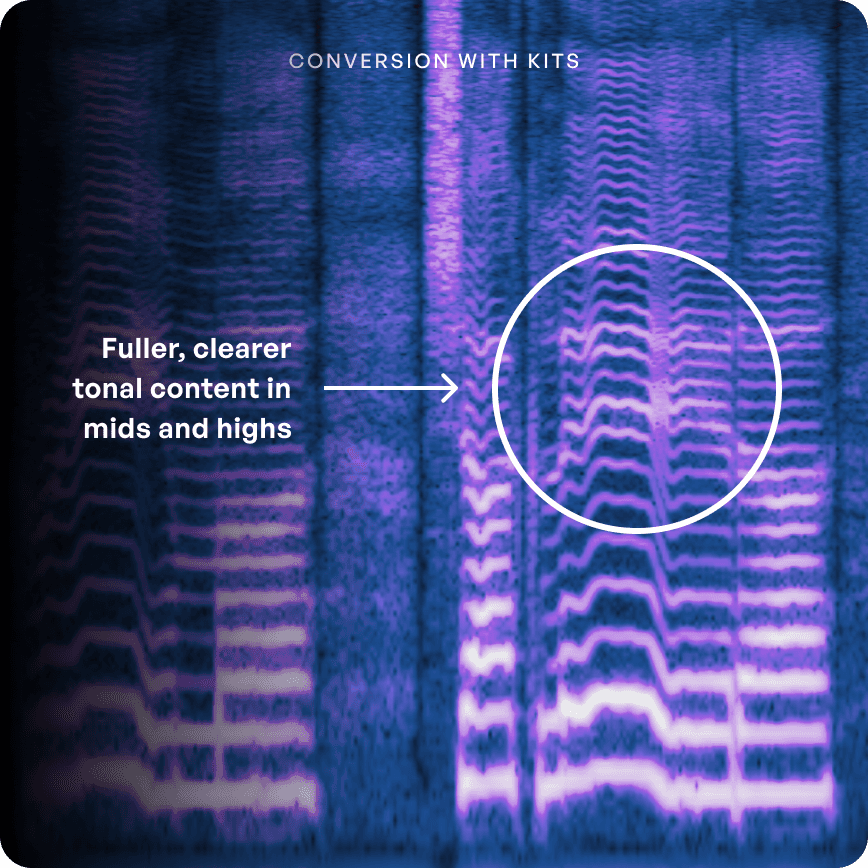
오픈 소스 가중치는 주로 음성 데이터에 대해 훈련되는 반면, Kits의 사전 훈련된 가중치는 노래에 최적화되어 있습니다. 그 결과: 가수의 음역대 전반에 걸쳐(그리고 그 너머까지) 더욱 풍부하고 선명한 음이 만들어집니다.
오픈 소스 사전 훈련 모델 (VCTK)
사전 훈련된 키트
킷을 사용하면, 오픈 소스 미리 학습된 가중치로는 재현하기 어려운 보컬 퍼포먼스의 뉘앙스가 훨씬 더 현실적으로 재현됩니다.
윤리적 AI에 대한 헌신
우리는 다음 세대의 음악 프로듀서를 강화하는 것이 이를 가능하게 하는 아티스트를 권한 부여하는 것에서 시작된다고 믿습니다. 그래서 Kits.AI의 연구는 아티스트로부터 직접 수집된 라이센스된 훈련 데이터에만 의존합니다.
우리의 로열티 없는 음성 및 악기 모델은 공정하게 훈련되었다고 인증받았으며, 이는 소싱부터 관리까지 우리 데이터 파이프라인의 모든 부분이 공정성을 위해 검토되었다는 것을 의미합니다. 이것은 단순한 배지가 아니라 우리가 운영하는 창의 산업에 기여하겠다는 약속입니다.
Kits.AI에서는 AI 기술 그 이상을 구축하고 있습니다. 우리는 업계의 새로운 기준을 설정하는 윤리적이고 고품질의 음악 제작 도구를 위한 토대를 만들고 있습니다. 우리는 음성 라이브러리를 계속 확장하고 모델을 개선하는 동안, 품질, 투명성 및 혁신에 대한 헌신을 유지하며, 프로듀서들이 신뢰할 수 있는 도구로 힘을 실어주고 있습니다.