
연구
제로샷 노래 음성 변환 소개
2024년 12월 9일
아나스타시아 헤루스에 의해
우리는 음악 제작자를 위한 가장 강력한 도구를 제공하기 위한 사명으로 Kits.AI 연구팀이 세계 최초의 제로 샷 싱잉 보이스 변환(ZS-SVC) 모델 중 하나를 개발했습니다. 이 모델은 훈련 없이 오디오를 대상 가수의 목소리로 변환할 수 있게 해줍니다.
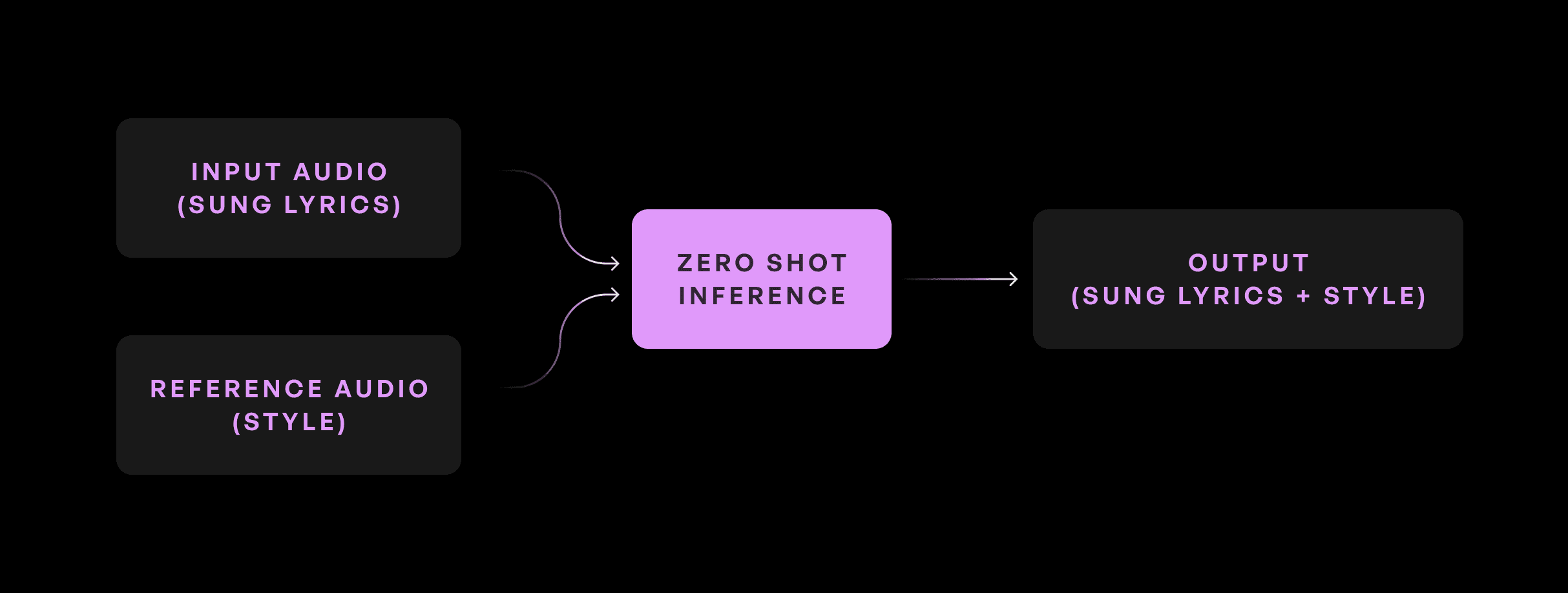
입력
대상 가수 참조
출력
건축과 데이터
제로샷 모델 아키텍처는 KVC 아키텍처,의 내용 인코딩, 피치 인코딩 및 검색을 포함한 여러 핵심 구성 요소를 상속받습니다. 주요 추가 사항은 참조 파일에서 가수 임베딩을 계산하는 가수 인코더 모듈입니다. 가수 임베딩은 변환에 사용될 수 있는 목표 가수의 보컬에 대한 분리된 표현입니다.
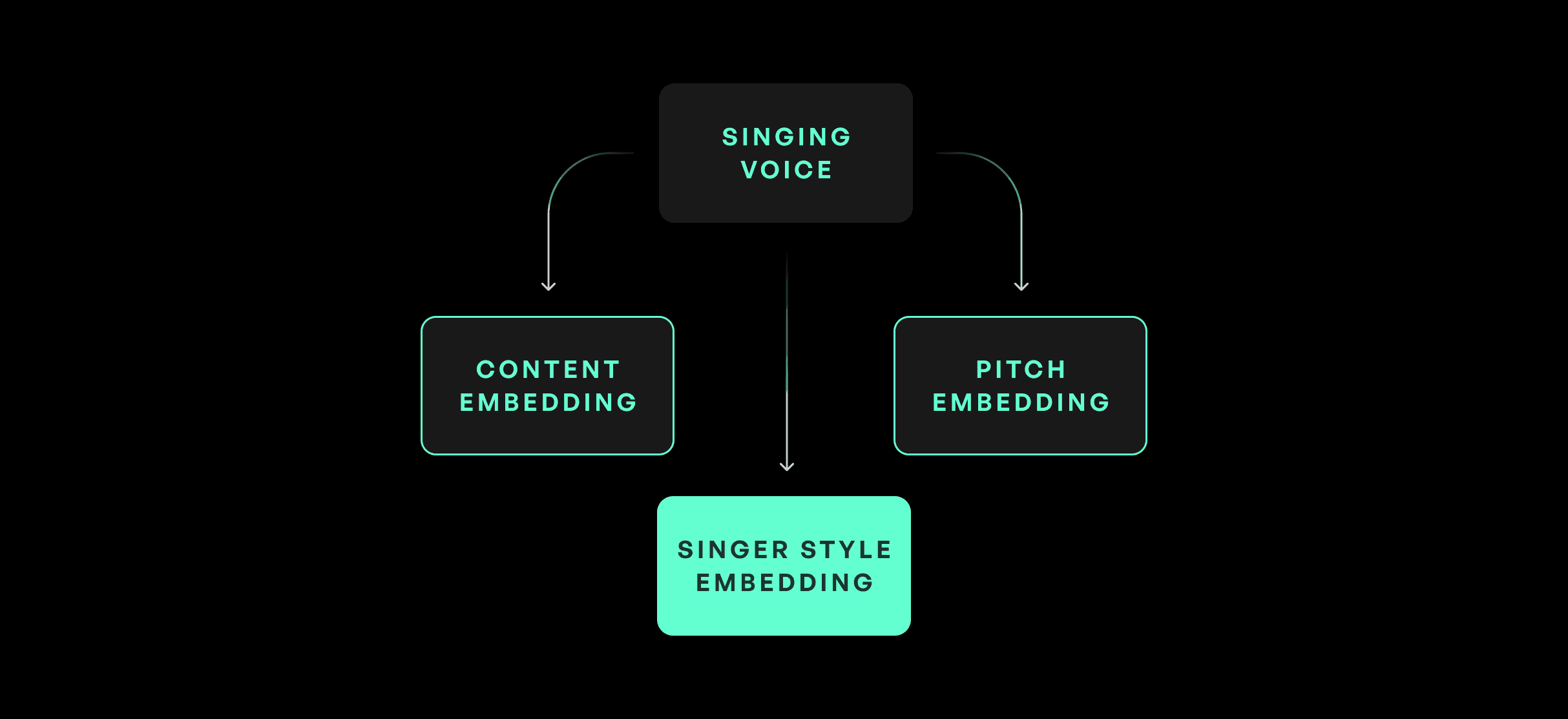
악센트 보존을 위한 음소 검색
레퍼런스 화자의 음색 품질을 보존하는 것을 넘어서, ZS-SVC 모델은 음소 검색 시스템도 사용합니다. KVC의 검색과 유사하게, 이는 목표 화자의 억양을 보존하는 데 도움을 주며, 과도한 수정으로 인한 발음 오류를 방지합니다.
데이터
데이터 품질을 양보다 우선시하는 최적화는 제로 샷 노래의 결과에 매우 영향을 미칩니다. ZS-SVC 모델은 Kits의 라이센스된 스튜디오 녹음 보컬 데이터셋으로 훈련되었습니다. 모든 데이터는 아티스트로부터 직접 라이센스를 받아오고, 오디오 엔지니어에 의해 수작업으로 전처리되어 발매 수준의 품질을 달성했습니다.
앞을 보며
ZS-SVC는 현재 Kits 베타 사용자에게 제공되는 새로운 즉각적인 음성 복제 (IVC) 기능을 지원합니다. ZS-SVC를 사용하는 더 많은 기능이 시간이 지나면서 더 넓은 Kits 커뮤니티에 제공될 것입니다.
음악 제작자들이 이 새로운 모델을 사용하여 그들의 창의적인 프로세스를 어떻게 발전시키는지 보는 것이 기대됩니다!