AI 노래 음성 훈련 및 맞춤화

작성자
게시됨
2024년 11월 6일
Kits의 주요 역할 중 하나는 우리의 로열티 없는 모델 이 멋지고 영감을 주는 데이터셋으로 훈련되도록 보장하는 것입니다. 이 과정의 일부는 순전히 기술적이며, 다른 부분은 모델의 특성을 형성하는 창의적인 선택으로 기울어집니다. 오늘은 여러분의 훈련 데이터를 최적화하고 목소리 모델에 독특한 개성을 추가하기 위해 의도적인 창의적 결정을 내리는 방법을 설명하겠습니다.
지난 몇 주 동안 제 기사는 우리 팀의 보다 개성 있는 목소리를 만드는 과정과 제가 사용한 독특한 기술들을 다뤘습니다. 제 남성 오버드라이브 록 모델을 위해 기타 앰프를 통해 노래를 부르거나 빈티지 여성 재즈 모델을 위해 제 스튜디오 모니터 중 하나를 캡처하기 위해 리본 마이크를 사용했든, 독특한 데이터셋을 만드는 방법은 정말 끝이 없습니다.
기초
탄탄한 기초는 어떤 목소리 모델을 만드는 데 가장 중요한 부분입니다. 추가하고 싶은 특별한 속성이 있더라도, 저는 항상 깨끗한 보컬 캡처부터 시작합니다. 이는 배경 소음– 에어컨, 냉장고 소음, 뭐가 숨어 있든 –을 제거하는 것을 의미합니다. 그런 소음들은 모델의 사운드를 저하시켜 나중에 문제를 일으킬 수 있습니다. 예를 들어 훌륭한 30분짜리 데이터셋을 녹음했지만 재생할 때 방에서 거의 눈치채지 못했던 낮은 허밍 소리가 들린다면 어떻게 하시겠습니까? 저도 그런 경험이 있습니다! 저는 한 테이크에 몰입한 후 나중에 앰프가 미친 듯이 윙윙거리거나 히터가 배경에서 돌아가는 소리를 캡처한 적이 있습니다. 고품질 보컬을 녹음하는 방법에 대한 가이드를 확인해보세요, 만약 당신이 처음부터 시작한다면.
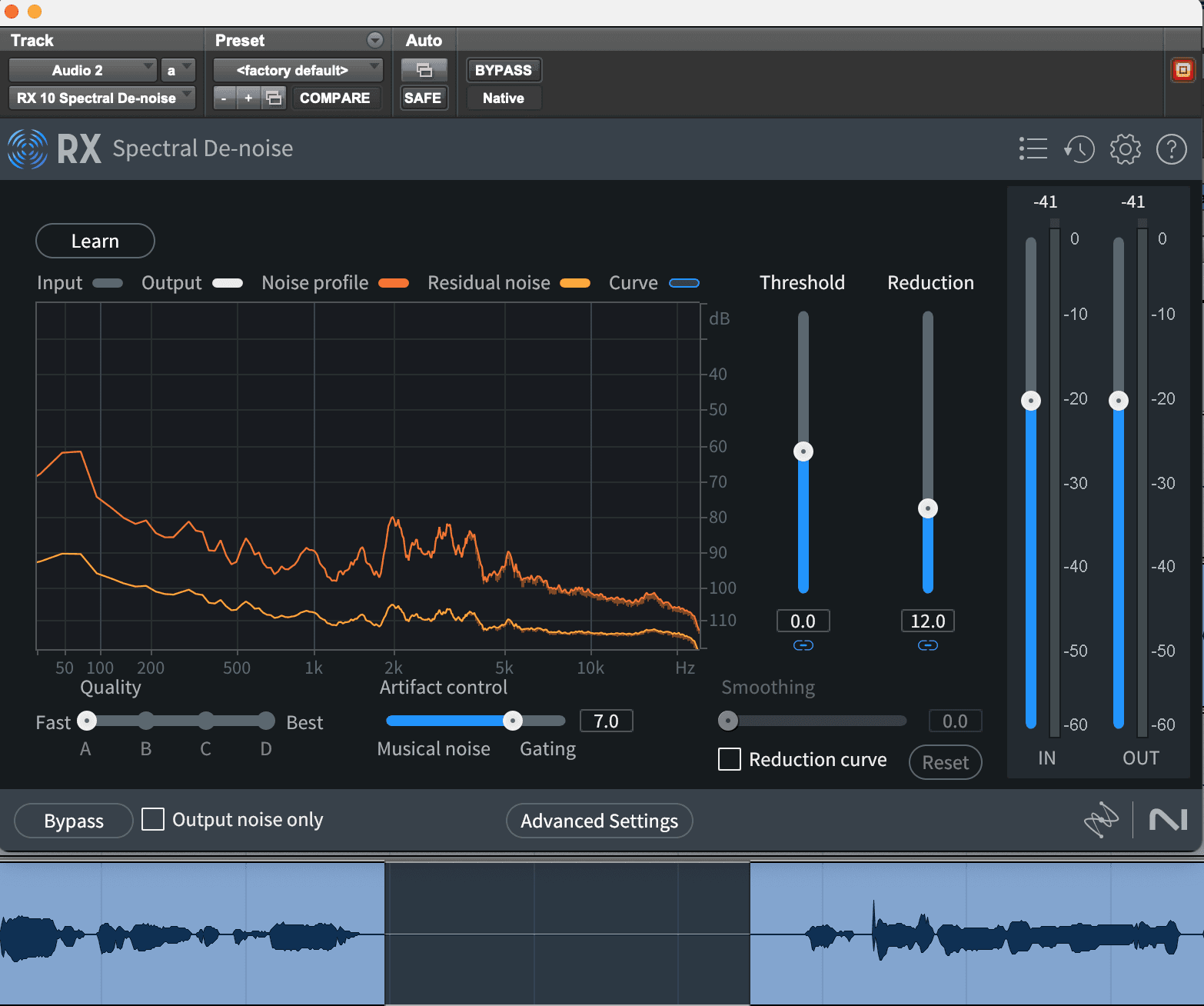
iZotope RX 같은 도구는 지속적인 허밍과 윙윙거리는 소리를 쉽게 수정할 수 있게 해줍니다. RX의 스펙트럴 디노이즈 모듈을 열고, 오직 배경 소음만 있는 오디오 섹션을 선택한 다음, “학습”을 클릭하고 오디오를 재생하세요. RX는 분석하고 자동으로 노이즈 감소를 조정할 것입니다. 임계값과 감소 슬라이더를 조정하여 더 미세하게 조정할 수 있지만, RX는 성가신 아티팩트를 제거하는 과정을 간략하게 만들어줍니다.
이득 수준이 중요하다
적절한 이득 수준을 설정하는 것도 매우 중요합니다. 모델을 만들 때 저는 -12dB 수준을 지속적으로 목표로 하며, 피크는 -6dB 이상이 되지 않도록 합니다. 이렇게 하면 오디오가 다이내믹하게 유지되며 머신 러닝에 효과적으로 훈련할 수 있는 이상적인 볼륨을 제공합니다. 종종 저는 너무 낮은 볼륨이거나 빨간색에서 클리핑되는 제출물을 봅니다. 디지털 클리핑은 락 보컬에서 원하는 기분 좋은 포화를 제공하지 않으며–그저 거칠고, 머신 러닝 알고리즘도 좋아하지 않습니다.

캐릭터 만들기
깨끗하고 탄탄한 데이터셋이 일반적으로 최고의 기초이지만, 때때로 DAW에 가져온 후 직접 캐릭터를 조작할 수 있는 재미도 있습니다. 효과가 적용된 어떤 소리를 업로드하더라도, 그것은 귀하의 모델에 자동으로 그 품질을 전달합니다 – 나중에 DAW 마법이 필요 없습니다. 이것은 특정 보컬 분위기에 접근하고자 하는 콘텐츠 제작자 에게 완벽할 수 있습니다, 예를 들어 높은 중주파수를 강조하고 약간의 거칠기를 더하는 라디오 또는 무전기 효과와 같은 것이죠. 이것을 전체 데이터셋에 적용하면, 마치 라디오를 통해 나오는 것처럼 즉시 들리는 모델이 생성됩니다.

혹시 그 구석에 있는 오래된 디스토션 페달을 dust off 할 시간인가요? 데이터를 그것을 통해 실행하면 완전히 새로운 수준의 보컬 캐릭터를 추가할 수 있습니다.

저는 종종 보컬을 기타 앰프를 통해 실행하는 것을 좋아합니다 – 오버드라이브를 극대화하고 기호에 맞게 조정합니다. 왜 당신의 마샬 하프스택을 통해 쏘고 이웃들이 경찰을 부르기까지 얼마나 걸릴지 한 번 확인해보지 않나요!

하지만 아마 당신은 소음 불만을 피하고 싶을 수도 있으며 대신 이 작은 배터리 구동의 마샬 중 하나를 시도해보는 게 좋을 것입니다. (부수적인 언급: 이작은 앰프는 스튜디오의 황금입니다 – 지나치지 마세요!)

또 다른 팁? 와 페달입니다. 특정 지점에서 와를 “고정”하면 필터링된 효과 범위를 넓게 만들어냅니다. 여기서 특별한 손길이 필요하지 않습니다; 일반적인 Dunlop CryBaby가 훌륭하게 작동합니다.

리얼 테이프 데크 없이 정통한 로파이 느낌을 원하신다면, 카세트 레코더를 시도해보세요. 이 하나는 내장 마이크와 USB 2.0 포트를 특징으로 합니다. 내장 마이크를 사용하여 스피커에서 카세트로 녹음하면 아름답게 저하된 따뜻한 소리를 만들어낼 수 있습니다. 저도 하나가 필요할 것 같습니다 – 실험하기에 완벽하거든요!

결론
결국 음악을 만드는 것은 즐거워야 하며, 저에게 그것은 경계를 허물고 새로운 소리를 찾는 것을 의미합니다. 첫 번째 업로드 시도가 원하는 대로 되지 않더라도 걱정하지 마세요 – 모든 테이크는 과정의 일부분이며, 여러분의 다음 행동에 정보를 제공합니다. Kits.AI 는 여러분이 영감을 주고 독특한 것을 창조하는 데 도움을 주기 위해 여기 있습니다. 그러니 도전해보세요 – 하늘이 한계입니다!
-SK
Sam Kearney 는 콜로라도 에버그린에 기반을 둔 프로듀서, 작곡가 및 사운드 디자이너입니다.
