Treinamento e Personalização da Voz de Canto de IA

Escrito por
Publicado em
6 de novembro de 2024
Um dos meus principais papéis na Kits é garantir que nossos modelos royalty-free sejam treinados com conjuntos de dados sólidos e inspiradores que não apenas soem bem, mas que sejam inspiradores para trabalhar. Algumas partes desse processo são puramente técnicas, enquanto outras se inclinam para escolhas criativas que moldam o caráter do modelo. Hoje, vou explicar como otimizar seus próprios dados de treinamento e tomar algumas decisões criativas intencionais para adicionar uma personalidade única aos seus modelos de voz.
Nas últimas semanas, meus artigos cobriram meu processo para criar algumas das nossas vozes mais baseadas em personagens e as técnicas únicas que utilizei. Se foi cantar através de um amplificador de guitarra para meu modelo Male Overdrive Rock ou usar um microfone de fita para capturar um dos meus monitores de estúdio para Vintage Female Jazz, as maneiras de criar um conjunto de dados destacado são verdadeiramente infinitas.
A Fundação
Uma base sólida é a parte mais crucial da criação de qualquer modelo de voz. Independentemente de quaisquer atributos especiais que eu possa querer adicionar, sempre começo com uma captura vocal limpa. Isso significa remover ruídos de fundo–ar condicionados, zumbidos de geladeira, o que quer que esteja à espreita–que podem degradar o som do seu modelo e criar problemas no futuro. Digamos que você gravou um ótimo conjunto de dados de 30 minutos, mas na reprodução, você ouve um zumbido baixo que era quase imperceptível na sala. Já passei por isso! Eu me perdi em uma gravação, apenas para depois pegar um amplificador zumbindo loucamente ou o aquecedor funcionando ao fundo. Confira nosso guia sobre como gravar vocais de alta qualidade você mesmo se você estiver começando do zero.
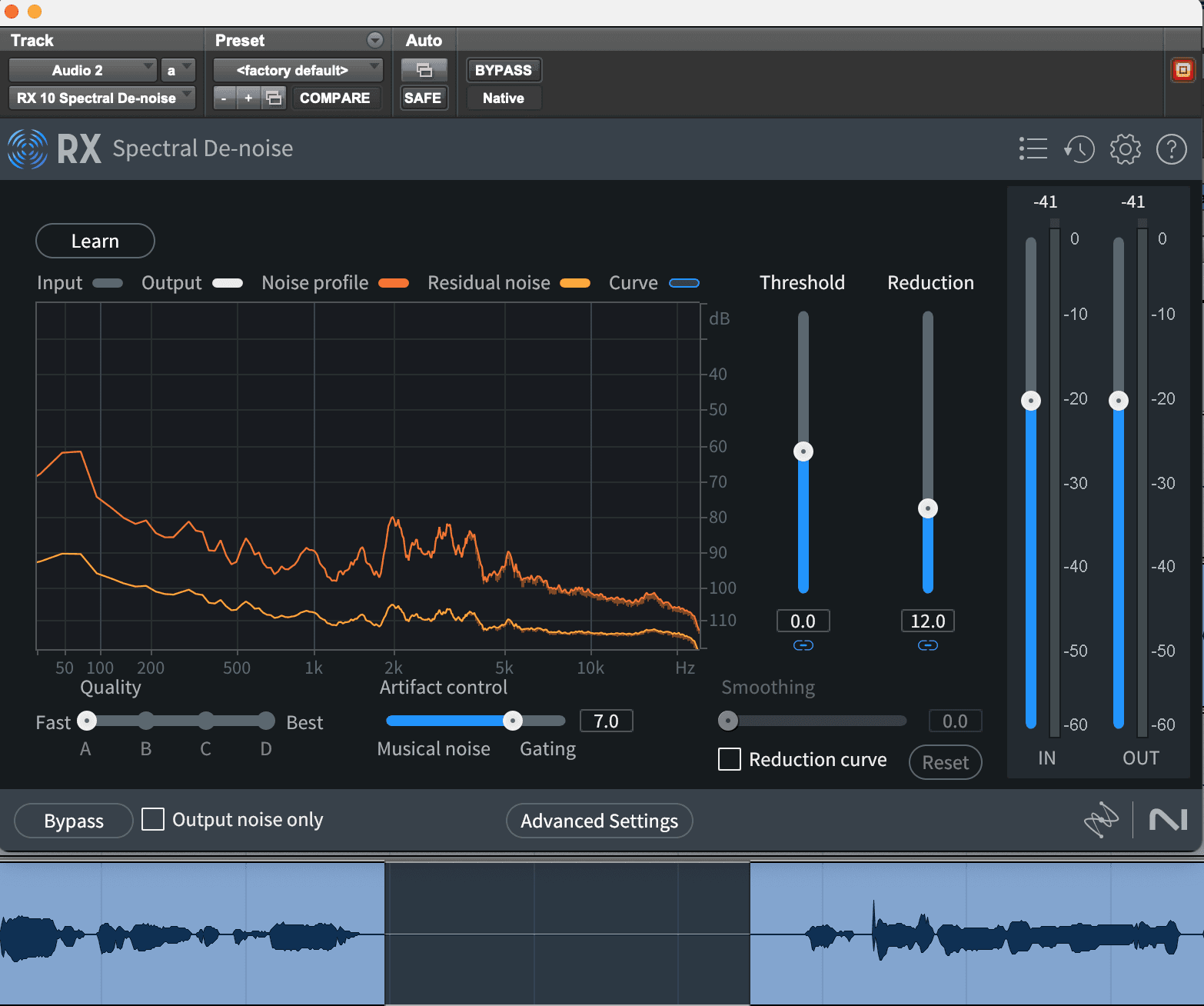
Uma ferramenta como iZotope RX facilita corrigir zumbidos e ruídos consistentes. Basta abrir o módulo Spectral De-noise do RX, selecionar uma seção do seu áudio que tenha apenas o ruído de fundo, clicar em "Aprender" e reproduzir o áudio. O RX analisará e ajustará automaticamente sua redução de ruído. Você pode querer ajustá-lo mais, alterando o controle de Limite e Redução, mas o RX simplifica a remoção desses artefatos incômodos.
Nível de Ganho Importa
Definir um nível de ganho adequado também é fundamental. Ao criar modelos, meu objetivo é um nível consistente de -12dB, com picos não superiores a -6dB. Isso permite que o áudio permaneça dinâmico enquanto dá ao aprendizado de máquina o volume ideal para treinar efetivamente. Eu frequentemente vejo submissões que estão ou muito baixas em volume ou cortando no vermelho. O clipe digital não proporciona aquela saturação agradável que você pode querer em um vocal rock–é apenas áspero, e os algoritmos de aprendizado de máquina também não são fãs.

Criando Caráter
Embora um conjunto de dados limpo e sólido seja geralmente a melhor base, permitindo que você manipule as coisas uma vez importadas para seu DAW, às vezes é divertido incorporar um pouco de caráter diretamente em seus dados de treinamento. Qualquer som que você enviar com um efeito aplicado carregará automaticamente essa qualidade em seu modelo–nenhuma mágica de DAW necessária depois. Isso pode ser perfeito para criadores de conteúdo que desejam acesso a uma vibração vocal específica, como um efeito de rádio ou walkie-talkie que enfatiza as frequências médias-altas e adiciona um pouco de textura. Aplique isso ao seu conjunto de dados inteiro, e você terá um modelo que instantaneamente soa como se estivesse saindo de um rádio.

Ou talvez seja hora de tirar aquele velho pedal de distorção do canto! Passar seu conjunto de dados por ele pode adicionar um novo nível de caráter vocal.

Eu gosto de passar vocais por um amplificador de guitarra–aumentando o overdrive e ajustando ao gosto. Por que não experimentar seu Marshall half-stack e ver quanto tempo leva até que seus vizinhos chamem a polícia!

No entanto, talvez você prefira evitar a reclamação de barulho e tente um desses pequenos Marshalls portáteis em vez disso. (Nota: esses amplificadores pequenos são ouro de estúdio–não os subestime!)

Outro truque? Um pedal wah. Manter um wah "travado" em certos pontos pode produzir uma ampla gama de efeitos filtrados. Não há necessidade de se complicar aqui; um padrão Dunlop CryBaby funciona muito bem.

E para uma vibração lo-fi autêntica sem a fita reel-to-reel, experimente um gravador de cassete. Este aqui possui um microfone embutido e uma porta USB 2.0. Usar o microfone embutido para gravar do seu alto-falante para cassete pode produzir um som degradado e quente de forma linda. Eu talvez precise pegar um desses para mim–perfeito para experimentar!

Conclusão
No final das contas, fazer música deve ser divertido, e para mim, isso significa ultrapassar limites e encontrar novos sons. Não se preocupe se sua primeira tentativa de upload não sair como você deseja–cada gravação é parte do processo, informando seu próximo movimento. Kits.AI está aqui para ajudar você a criar algo inspirador e único. Então, vá em frente–o céu é o limite!
-SK
Sam Kearney é um produtor, compositor e designer de som baseado em Evergreen, Colorado.
