Entraînement et personnalisation de voix chantées par IA

Écrit par
Publié le
6 novembre 2024
Un de mes principaux rôles chez Kits est de garantir que nos modèles sans droits d'auteur sont formés avec des ensembles de données solides et inspirants qui ne se contentent pas de bien sonner, mais sont inspirants à travailler. Certaines parties de ce processus sont purement techniques, tandis que d'autres s'inspirent de choix créatifs qui façonnent le caractère du modèle. Aujourd'hui, je vais expliquer comment optimiser vos propres données d'entraînement et prendre des décisions créatives intentionnelles pour ajouter une personnalité unique à vos modèles vocaux.
Au cours des dernières semaines, mes articles ont couvert mon processus pour créer certaines de nos voix plus basées sur le caractère et les techniques uniques que j'ai utilisées. Que ce soit en chantant à travers un amplificateur de guitare pour mon modèle Male Overdrive Rock ou en utilisant un microphone à ruban pour capturer l'un de mes moniteurs de studio pour Vintage Female Jazz, les façons de créer un ensemble de données exceptionnel sont véritablement infinies.
Les Fondations
Une base solide est la partie la plus cruciale de la création de tout modèle vocal. Peu importe les attributs spéciaux que je pourrais vouloir ajouter, je commence toujours par une capture vocale propre. Cela signifie supprimer le bruit de fond – climatiseurs, bourdonnement de réfrigérateurs, tout ce qui pourrait dégrader le son de votre modèle et créer des problèmes par la suite. Supposons que vous ayez enregistré un excellent ensemble de données de 30 minutes, mais lors de la lecture, vous entendez un léger bourdonnement qui était à peine perceptible dans la pièce. J'y ai déjà été ! Je me suis perdu dans une prise, pour ensuite constater qu'un amplificateur grondait furieusement ou que le chauffage fonctionnait en arrière-plan. Consultez notre guide sur comment enregistrer des voix de haute qualité vous-même si vous commencez de zéro.
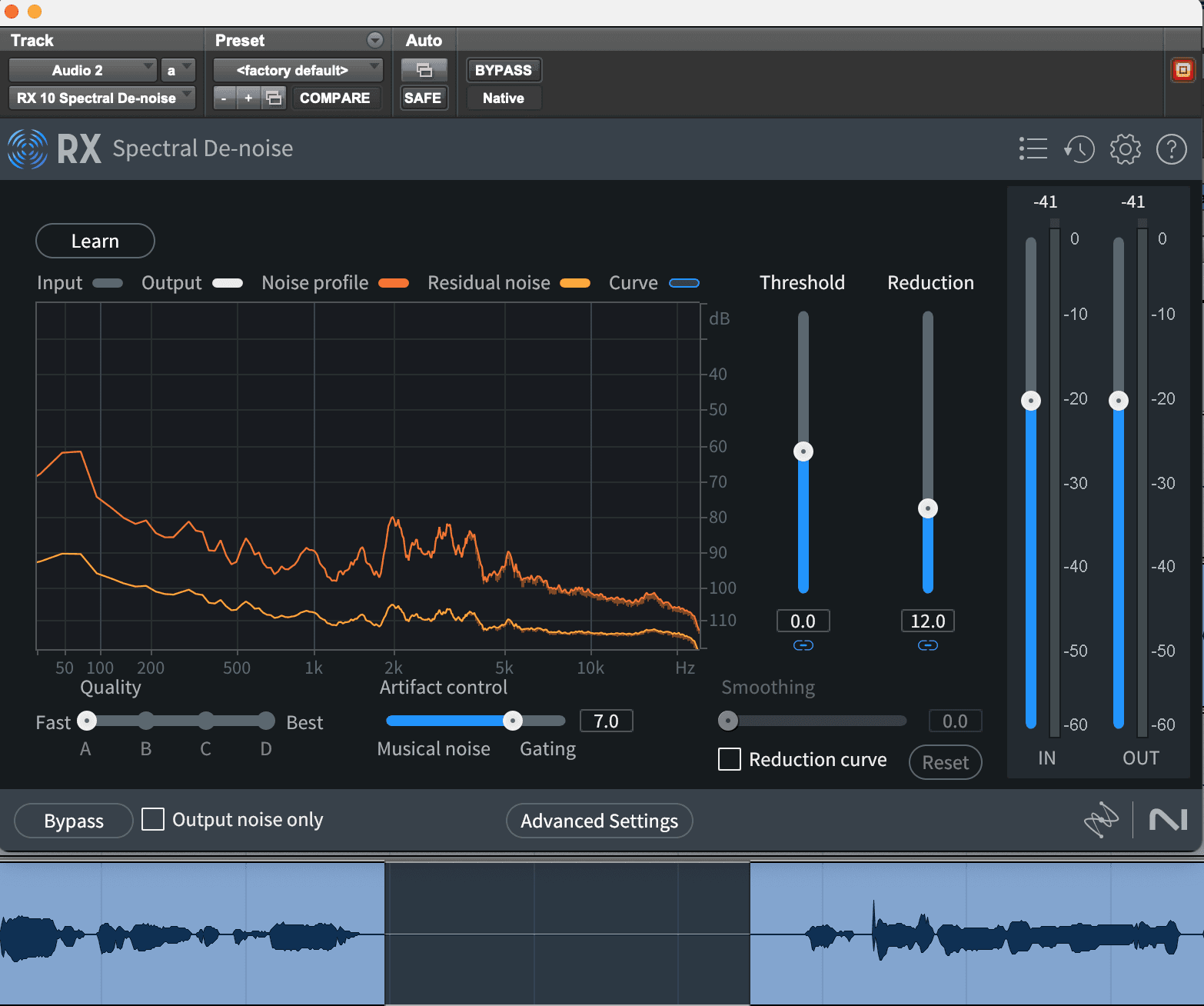
Un outil comme iZotope RX facilite la correction des bourdonnements et des grésillements récurrents. Il suffit d'ouvrir le module Spectral De-noise de RX, de sélectionner une section de votre audio avec uniquement le bruit de fond, d'appuyer sur « Apprendre » et de lire l'audio. RX analysera et ajustera automatiquement sa réduction de bruit. Vous voudrez peut-être le peaufiner davantage en ajustant les faders de seuil et de réduction, mais RX simplifie la suppression de ces artefacts ennuyeux.
Le Niveau de Gain Compte
Définir un niveau de gain approprié est également essentiel. Lors de la création de modèles, je vise un niveau constant de -12 dB, avec des pics ne dépassant pas -6 dB. Cela permet à l'audio de rester dynamique tout en donnant au machine learning le volume idéal pour s'entraîner efficacement. Je vois souvent des soumissions qui sont soit beaucoup trop basses en volume, soit qui saturent dans le rouge. La saturation numérique ne vous donnera pas cette saturation agréable que vous pourriez vouloir dans une voix rock – c'est juste brutal, et les algorithmes de machine learning ne sont pas fans non plus.

Créer du Caractère
Bien qu'un ensemble de données propre et solide soit généralement la meilleure base, vous permettant de manipuler les choses une fois importées dans votre DAW, il est parfois amusant de cuire un peu de caractère directement dans vos données d'entraînement. Tout son que vous téléchargez avec un effet appliqué portera automatiquement cette qualité dans votre modèle - aucune magie DAW n'est nécessaire plus tard. Cela peut être parfait pour les créateurs de contenu cherchant à accéder à une vibe vocale spécifique, comme un effet radio ou talkie-walkie qui met en avant les fréquences hautes et moyennes et ajoute un peu de grain. Appliquez cela à l'ensemble de vos données, et vous avez un modèle prêt à l'emploi qui sonne instantanément comme s'il sortait d'une radio.

Ou peut-être est-il temps de dépoussiérer ce vieux pédalier de distorsion dans le coin ! Faire passer votre ensemble de données à travers peut ajouter un niveau complètement nouveau de caractère vocal.

J'aime souvent faire passer les voix à travers un amplificateur de guitare – en poussant l'overdrive et en l'ajustant à mon goût. Pourquoi ne pas faire rugir votre Marshall et voir combien de temps il faut avant que vos voisins n'appellent les flics !

Cependant, peut-être préféreriez-vous éviter la plainte pour bruit et essayer l'un de ces petits Marshalls alimentés par batterie à la place. (Petite note : ces petits amplis sont de l'or en studio – ne les négligez pas !)

Une autre astuce ? Une pédale wah. Garder une wah « bloquée » à certains points peut produire une large gamme d'effets filtrés. Pas besoin de se compliquer ici ; une standard Dunlop CryBaby fonctionne parfaitement.

Et pour une ambiance lo-fi authentique sans le magnéto à bobines, essayez un enregistreur à cassette. Ce modèle dispose d'un microphone intégré et d'un port USB 2.0. Utiliser le microphone intégré pour enregistrer depuis votre enceinte sur cassette peut produire un son dégradé et chaud. Je vais peut-être devoir en attraper un moi-même – parfait pour expérimenter !

Conclusion
Au bout du compte, faire de la musique devrait être amusant, et pour moi, cela signifie repousser les limites et trouver de nouveaux sons. Ne vous inquiétez pas si votre première tentative de téléchargement ne se passe pas comme vous le souhaitez - chaque prise fait partie du processus, informant votre prochain mouvement. Kits.AI est là pour vous aider à créer quelque chose d'inspirant et d'unique. Alors foncez - les limites sont là où vous les fixez !
-SK
Sam Kearney est un producteur, compositeur et designer sonore basé à Evergreen, Colorado.