Erreurs courantes à éviter lors de l'utilisation de la voix artificielle

Écrit par
L'équipe Kits
Publié le
23 août 2024
Introduction
L'intégration d' AI Vocals (voix d'IA) dans votre musique est un outil passionnant et innovant pour les musiciens et les producteurs, grâce aux progrès de l'intelligence artificielle. Comme toute nouvelle technologie, elle nécessite quelques ajustements pour obtenir les meilleurs résultats. Chez Kits, nous traitons des ensembles de données pour créer des configurations idéales pour un entraînement de modèle vocal IA précis et réaliste. Au fil du temps, j'ai remarqué des erreurs courantes qui peuvent nuire à la performance des voix générées par IA. Dans cet article, je soulignerai ces pièges et proposerai des conseils sur la façon d'optimiser vos modèles vocaux IA.

Niveau et dynamique
La voix humaine est unique, un peu comme une empreinte digitale, avec son propre timbre et ses nuances émotionnelles. Le chant est généralement une forme d'expression émotionnelle accrue et peut naturellement varier en intensité. Lors de l'enregistrement des voix, ces variations sont souvent gérées à l'aide de techniques de micro et de compresseurs. Les chanteurs de session expérimentés peuvent « s'auto-compresser » en ajustant leur distance par rapport au micro pendant les sections fortes. Cependant, même avec cette technique, une compression supplémentaire est généralement nécessaire pour maintenir un mixage équilibré.
Tout comme la compression naturelle profite aux chansons, elle améliore également le processus d'entraînement des modèles vocaux IA. Chez Kits AI, nous avons constaté que les pistes vocales avec une plage dynamique contrôlée produisent de meilleurs résultats en matière de clonage vocal, en particulier lors de l'utilisation de logiciels avancés pour le traitement. Ma technique personnelle pour préparer une voix à l'entraînement consiste à importer la piste dans ma STAN (DAW), et à utiliser le gain de clip pour égaliser certaines des sections les plus extrêmes avant d'appliquer toute compression supplémentaire. Cela garantit que le compresseur fonctionne efficacement sans introduire de sons artificiels.
Dans l'image ci-dessous, la piste supérieure montre l'ensemble de données d'origine, tandis que la piste inférieure illustre mes ajustements de mise à niveau :

En utilisant cette approche, seule une légère touche de compression est nécessaire. Je recommande pas plus de 3 à 5 dB de réduction de gain.
Pour des résultats optimaux, visez un niveau de volume moyen de -12 dB avec des pics ne dépassant pas -6 dB. Cela fournit une excellente base pour l'apprentissage automatique et crée des modèles de voix IA plus réalistes.
De-ess pour réduire la sibilance agressive
La sibilance agressive, causée par des consonnes comme le « s », le « t » et le « z », peut être distrayante et désagréable dans les enregistrements vocaux. Un de-esser, tel que le Pro-DS de FabFilter, est essentiel pour contrôler ces sons brillants. Cela garantit que votre modèle de voix IA n'est pas entraîné à reproduire ces éléments agressifs, ce qui permet d'obtenir un résultat plus fluide et plus professionnel.
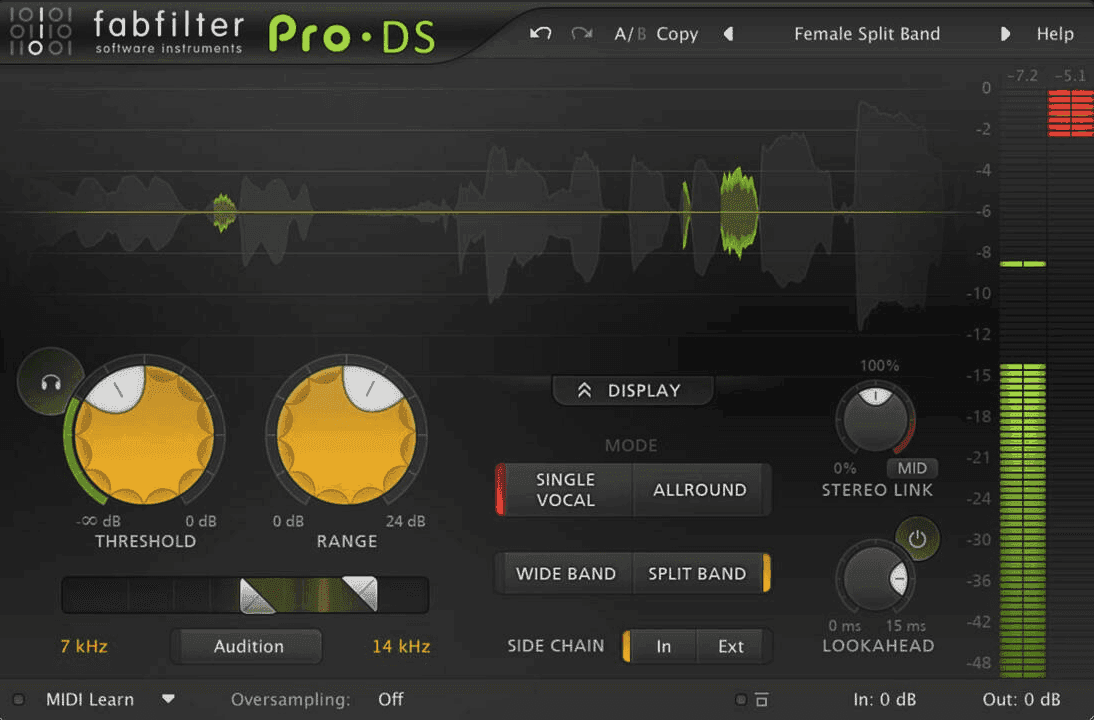
égaliseur : équilibrer le spectre
L'égalisation (EQ) joue un rôle crucial dans le façonnement du son d'un enregistrement vocal. Bien que les paramètres spécifiques de l'égaliseur puissent varier en fonction du contenu musical, un égaliseur bien équilibré peut considérablement améliorer la qualité de votre clone de voix IA et fournir un excellent point de départ pour quel que soit le contexte et le genre dans lesquels votre modèle de voix IA existera.
Commencez par un filtre passe-haut pour éliminer toutes les basses fréquences inutiles qui ne contribuent pas au ton de la voix. Cependant, faites attention lorsque vous dépassez 100 Hz, car cela pourrait éliminer des éléments importants du timbre vocal.
À l'autre extrémité du spectre, méfiez-vous de toutes les hautes fréquences agressives qui peuvent être introduites par des microphones beaucoup plus abordables. Tout le monde n'a pas un vieux Neumann pour chanter (moi y compris). Un filtre passe-bas peut aider à maîtriser ces fréquences, généralement autour de 20 kHz et au-delà.
L'utilisation d'un égaliseur comme le Pultec EQP-1A, connu pour son caractère doux et chaleureux, est un excellent choix pour nettoyer les grondements de bas de gamme et adoucir les aigus.

Correction de hauteur : quand et comment l'utiliser
Les outils de correction de hauteur (pitch correction) sont souvent utilisés comme effet dans la production musicale moderne. Cependant, lors de l'entraînement d'un modèle de voix IA, je recommande de garder les voix naturelles et d'appliquer la correction de hauteur après que la voix a déjà été clonée. Cette approche préserve le réalisme de votre modèle IA et offre une flexibilité pour les futurs projets qui pourraient nécessiter un son plus naturel.
Variété vocale : élargissez votre matériel source
L'une des erreurs les plus courantes dans l'entraînement vocal IA est le manque de variété dans l'ensemble de données vocales. Les modèles d'apprentissage automatique ne peuvent s'entraîner qu'à partir du matériel fourni, de sorte qu'un ensemble de données limité se traduit par un modèle vocal limité. Pour préciser, j'ai reçu des soumissions qui incluent des chanteurs interprétant la même chanson encore et encore. Bien qu'ils puissent sembler formidables sur cette unique chanson, je sais qu'ils sont capables d'atteindre des hauteurs de notes plus élevées et plus basses, d'exprimer des inflexions vocales plus intenses et plus douces, tout cela ne sera pas inclus dans leur modèle vocal parce que l'apprentissage automatique n'a pas accès à ces informations supplémentaires. À son tour, cela fournira un cas d'utilisation très limité pour un modèle de voix IA.
To create versatile AI voices, include a wide range of vocal performances in your training material. This should cover different pitches, emotional expressions, and vocal techniques, including both chest and falsetto voices, to mimic the versatility of a real artist. Although the minimum requirement is 15 minutes of audio, I recommend utilizing the full 30 minutes to capture the full range of the vocalist’s abilities.

Supprimer les espaces vides
Les soumissions vocales sont souvent des versions a cappella de chansons dans leur intégralité. Étant donné que le processus d'apprentissage automatique ne se soucie que de l'analyse d'une performance vocale, les longs espaces vides, qui peuvent être des sections instrumentales d'une chanson entière, ne sont pas nécessaires et prennent un temps précieux dans l'ensemble de données. Pour optimiser votre modèle de voix IA, supprimez toutes les sections non vocales et assurez-vous que l'audio soit continu, comme indiqué dans mon premier exemple ci-dessus. L'utilisation de cette approche maximisera les données d'entraînement et aidera votre modèle à conserver autant de réalisme que possible.
Exportez votre audio en véritable mono
Enfin, exportez toujours vos pistes vocales (stems) sous forme de véritables pistes mono. Soumettre des pistes stéréo, même si l'enregistrement était en mono, double les données perçues et réduit la quantité de matériel utilisable pour l'entraînement. Pour obtenir les meilleurs résultats de clonage vocal, maximisez la quantité de matériel sur laquelle votre modèle peut être entraîné en exportant votre piste vocale en mono avant de la téléverser sur Kits.AI.
Conclusion
En suivant ces conseils, vous pouvez éviter les erreurs vocales courantes de l'IA et commencer à libérer tout le potentiel de ce puissant outil. N'oubliez pas que l'IA n'est pas un outil créatif, c'est l'outil d'un créateur. Comme tous les nouveaux outils et technologies émergentes, il y a une courbe d'apprentissage, mais avec la bonne approche, intégrer des voix d'IA dans votre musique peut ouvrir de nouvelles possibilités qui étaient autrefois inimaginables.
Commencez, c'est gratuit.
Optimisez votre flux de production vocale avec des outils audio AI de qualité studio
